We are living in the golden age of Edge AI. Embedded engineers are no longer just writing firmware to read sensor data and toggle GPIO pins; we are deploying deep learning models directly onto microcontrollers (MCUs) and field-programmable gate arrays (FPGAs). However, the reality of deploying machine learning in “the wild” is far messier than the pristine conditions of a training dataset. Welcome to the relentless challenge of model drift.
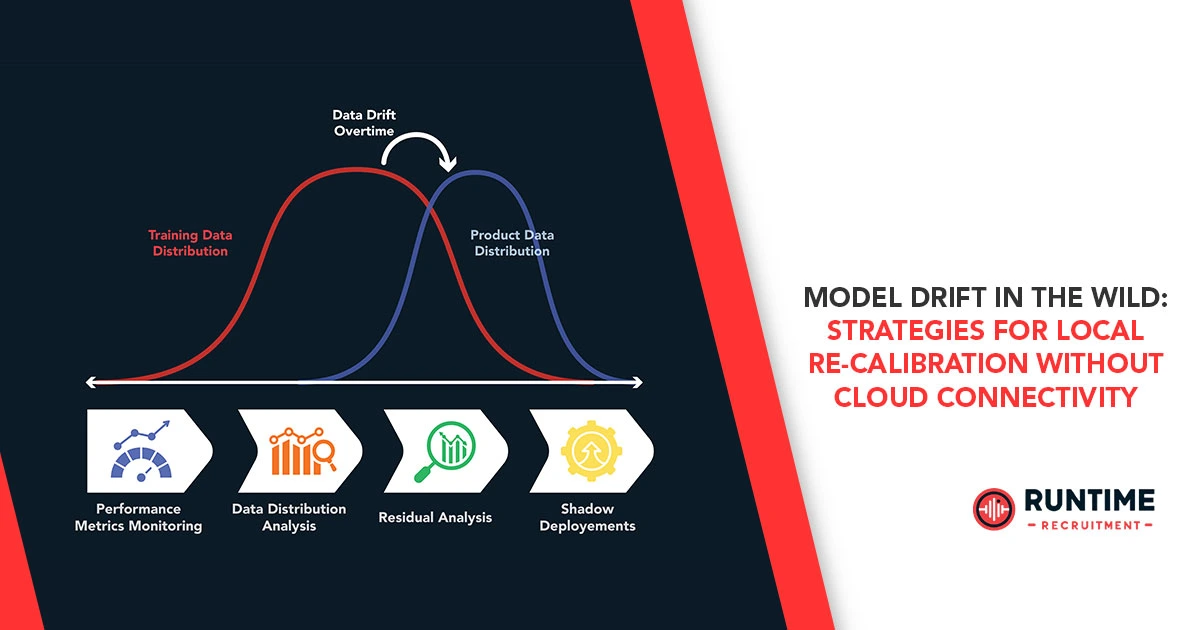
When a machine learning model is trained, it learns a static representation of a specific environment. But physical environments are dynamic. Sensors degrade, ambient temperatures fluctuate, lighting conditions shift, and mechanical components wear down over time. This divergence between the data the model was trained on and the data it encounters in production is known as model drift. Left unchecked, drift leads to silent failures, degrading accuracy until the intelligent system becomes actively detrimental.
The traditional software engineering solution to this problem is simple: push the new data to the cloud, retrain the model on massive GPU clusters, and deploy an over-the-air (OTA) update. But what happens when you don’t have a reliable cloud connection? Whether you are monitoring an offshore wind turbine, running predictive maintenance on deep-underground mining equipment, or operating low-power agriculture sensors in remote areas, continuous cloud connectivity is often a luxury you cannot afford. Latency, bandwidth costs, power budgets, and privacy regulations make cloud-tethered retraining impossible in many embedded applications.
For modern engineering leaders—who must balance data-driven innovation with the hard constraints of hardware—the solution lies in localized, on-device intelligence. In this article, we will explore practical strategies for handling model drift directly on embedded devices, ensuring your systems remain resilient, adaptive, and highly accurate without ever needing to phone home to the cloud.
Understanding Model Drift in Embedded Environments
To solve the problem, we first need to dissect it. Model drift generally falls into two primary categories that embedded systems engineers need to monitor:
- Data Drift (Covariate Shift): This occurs when the distribution of the input data changes, even if the underlying relationship between the input and the target variable remains the same. In embedded hardware, this is frequently caused by sensor degradation, changes in environmental noise, or slight voltage fluctuations affecting analog-to-digital converter (ADC) readings over time.
- Concept Drift: This is a more complex failure mode where the statistical relationship between the input data and the target output fundamentally changes. For instance, an AI model designed to detect “normal” vibration in an industrial motor might experience concept drift if a new, heavier load is permanently attached to the motor. What was previously classified as an “anomaly” is now the baseline normal.
Detecting these shifts natively on an edge device with strict memory constraints (often mere kilobytes of SRAM and Flash) is a major architectural hurdle. Traditional drift detection relies on calculating statistical distance metrics over large batches of historical and current data. On a resource-constrained MCU or custom edge AI accelerator, storing massive batches of historical data is structurally impossible. Therefore, engineers must pivot toward sequential, streaming-based detection algorithms that update statistical representations of the data one sample at a time, minimizing memory footprint and CPU cycles.
The Perils of Cloud-Dependency at the Edge
Before diving into local recalibration techniques, it is worth cementing why cloud-based retraining is often a flawed paradigm for true edge deployments. Modern engineering managers are moving away from centralized architectures due to several compounding factors:
- Intermittent Connectivity: Devices in the field frequently experience cellular dropouts, RF interference, or exist entirely outside of network coverage areas. A model that relies on cloud updates to fix performance drops will be out of commission during the exact moments it is needed most.
- Power Constraints: Radio transmissions (Wi-Fi, Cellular, LoRaWAN) are often the most power-hungry operations on a printed circuit board (PCB). Sending high-fidelity sensor data to the cloud for retraining drastically reduces battery life. For green, sustainable embedded architectures—a growing priority in modern engineering culture—minimizing transmission time is critical to achieving multi-year battery lifespans and reducing the overall carbon footprint of the device.
- Latency: In real-time operating system (RTOS) environments, deterministic execution is paramount. Waiting for a cloud server to acknowledge drift and send down new weights introduces unacceptable latency in safety-critical systems.
- Privacy and Security: Transmitting raw data off-device opens up attack vectors. Local processing inherently enforces data minimization, ensuring that sensitive telemetry never leaves the physical boundary of the embedded hardware.
Strategies for Local Re-Calibration
Solving drift offline requires a paradigm shift from static inference engines to continuous, event-driven learning architectures. Here are the leading strategies for achieving local re-calibration.
1. Sequential and On-Device Incremental Learning
The Holy Grail of adapting to drift is allowing the model to train itself on the device. However, standard neural network backpropagation requires significant memory to store gradients and activations, making it unfeasible for low-end edge devices.
Instead, forward-thinking embedded teams are turning to sequential or incremental learning techniques. Rather than retraining the entire deep neural network, the architecture is frozen up to the penultimate layers, which act as fixed feature extractors. Only the final classification or regression layer is updated using lightweight mathematical techniques.
One method involves using a k-Nearest Neighbors (k-NN) classifier or a Support Vector Machine (SVM) on top of the frozen neural network features. As the device encounters new data that is confidently verified by secondary sensors or user feedback (ground truth), it slowly replaces older data points in its memory buffer with new ones, shifting its decision boundaries in real time. Recent advancements in the field have demonstrated fully sequential concept drift detection methods that reduce memory size by over 90% compared to batch-based methods, allowing complex adaptation algorithms to run on hardware as small as a Raspberry Pi Pico.
2. Pre-Trained Polymorphism and Virtual Models
If on-device training is still too computationally expensive for your specific power budget, a highly effective alternative is deploying polymorphic virtual models.
In this strategy, the engineering team pre-trains multiple lightweight models (or sub-models) for different environmental states. For example, a predictive maintenance sensor deployed on outdoor railway tracks might experience drastic data shifts between summer and winter. Instead of retraining a model to understand both, or trying to adapt the model dynamically, the device holds “Summer,” “Winter,” and “Transitional” models in its Flash memory.
The system utilizes a lightweight heuristic or an event-driven trigger—such as an onboard temperature sensor crossing a specific threshold or a calendar timestamp—to swap the active model from Flash into SRAM. This allows the embedded device to adapt to known environmental shifts instantly, simulating on-device learning without executing a single backpropagation cycle. This approach heavily reduces the carbon cost of compute, aligning with energy-efficient, eco-conscious hardware design principles while mitigating e-waste by extending device lifecycles.
3. Adaptive Thresholding and Output Calibration
Sometimes, the model’s feature extraction is still perfectly valid, but the output probabilities become skewed due to environmental noise. In these cases, you do not necessarily need to update the model weights; you need to recalibrate how you interpret the model’s output.
Consider a classification model outputting a confidence score between 0.0 and 1.0. Originally, a threshold of 0.8 might have been the perfect cutoff for triggering a system alert. However, as the hardware ages and sensor noise increases, the model’s maximum confidence might drop to 0.75, causing it to miss critical events entirely.
Local recalibration can be achieved by writing dynamic thresholding algorithms within the firmware. By continuously calculating proxy metrics—such as tracking the rolling average of output probabilities—the device can automatically lower or raise its decision threshold to maintain a consistent alert rate. This is an elegant, low-compute strategy that engineering managers can implement rapidly to buy time and extend the usable life of deployed edge models without requiring complex machine learning operations (MLOps) infrastructure.
4. Localized Federated Learning (The Mesh Approach)
When cloud connectivity is absent, embedded devices can still collaborate if they exist on a local mesh network (such as Thread, Zigbee, or a local Wi-Fi intranet). This opens the door to offline federated learning or “Fog Computing.”
In a modern manufacturing plant, dozens of identical robotic arms might be running the same edge AI model. If one arm experiences drift and locally recalibrates its threshold or final classification layer, it can broadcast these updated, lightweight parameters to the local gateway or directly to peer devices. The local network aggregates these insights and redistributes an improved consensus model. This allows the entire local ecosystem to learn from the wear-and-tear experienced by a single node, ensuring robustness across the factory floor without ever crossing the corporate firewall or reaching the public internet.
Hardware and Energy Considerations for Adaptive AI
Implementing these strategies requires a modern approach to embedded hardware selection. Today’s engineering leaders understand that throwing a larger, power-hungry processor at a problem is an outdated methodology. True engineering elegance lies in optimization.
When designing architectures for local re-calibration, careful consideration must be given to memory hierarchies. Because writing to standard Flash memory degrades it over time, incremental learning weights should ideally be managed in SRAM or specialized non-volatile memory (like FRAM) that can handle high write cycles. Furthermore, utilizing dedicated Neural Processing Units (NPUs) or modern neuromorphic chips can drastically accelerate the vector math required for both inference and incremental updates, keeping the overall power consumption squarely in the microwatt range.
The push toward green embedded architectures necessitates that we write “carbon-conscious code.” Avoiding cloud transmissions in favor of highly optimized, localized matrix multiplication is a significant step toward reducing the massive energy footprints associated with modern AI, demonstrating a commitment to responsible, forward-thinking engineering.
Conclusion
Deploying an AI model to an edge device is not the finish line; it is the starting gun. Model drift is an inevitable reality of physical engineering, driven by sensor degradation, changing climates, and mechanical wear. For applications where cloud connectivity is intermittent, costly, or insecure, relying on centralized retraining is an architectural vulnerability.
By embracing sequential on-device learning, polymorphic model swapping, dynamic thresholding, and localized mesh collaboration, embedded engineers can design intelligent systems that adapt autonomously. These self-healing, locally recalibrated systems represent the true promise of Edge AI: devices that don’t just compute, but actually survive and evolve in the wild. As we continue to push the boundaries of embedded capabilities, building systems capable of navigating concept drift locally will become a definitive hallmark of robust, professional engineering.
Looking to build a high-performing team capable of tackling the toughest challenges in embedded systems and Edge AI? Secure the technical talent you need to drive your next-generation projects.







