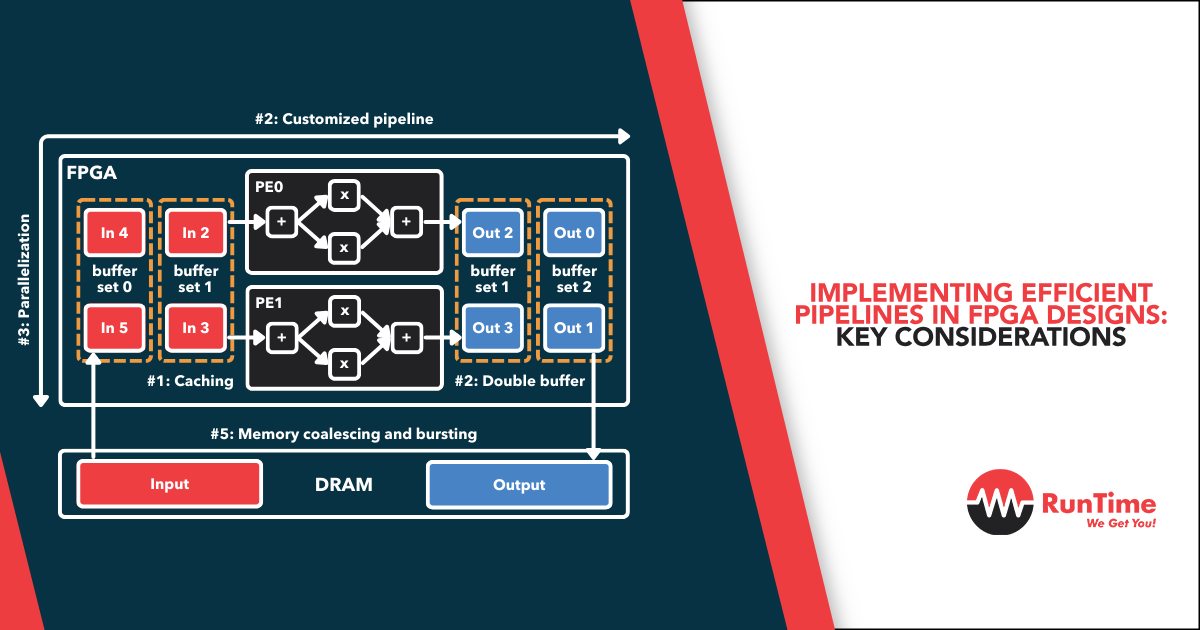
Field Programmable Gate Arrays (FPGAs) are a crucial technology in embedded systems, offering a high degree of parallelism, configurability, and performance for custom hardware implementations. One of the most powerful design techniques to leverage FPGAs’ strengths is pipelining, which allows for increased throughput by breaking a task into smaller stages, each executed in parallel by dedicated hardware blocks. This article explores key considerations for implementing efficient pipelines in FPGA designs, helping engineers achieve optimal performance in real-world applications.
What is Pipelining in FPGA Design?
Pipelining is a design technique where an operation is divided into multiple stages, with each stage performing a part of the overall task. Instead of executing one operation sequentially, pipelining allows multiple operations to be processed simultaneously, with each stage in the pipeline working on a different task at the same time.
In FPGA designs, pipelining is often used to accelerate data processing tasks, such as filtering, encoding, or signal processing. By spreading the workload across multiple stages, FPGAs can achieve significantly higher throughput compared to traditional sequential execution. However, designing an efficient pipeline on an FPGA requires careful consideration of various factors, including timing, resource allocation, latency, and data dependencies.
1. Understanding Latency vs. Throughput in Pipelining
One of the fundamental trade-offs in FPGA pipelining is between latency and throughput. Latency refers to the total time it takes for an input to propagate through the entire pipeline and produce an output. In contrast, throughput is the number of outputs the system can produce per unit of time.
In a deeply pipelined design, each stage is relatively simple, leading to high throughput. However, this can increase latency because a piece of data must pass through all stages before being completely processed. This trade-off is acceptable in applications where continuous, high-speed data processing is required (e.g., real-time video processing or signal filtering).
Conversely, in applications where low latency is critical, such as control systems or feedback loops, designers may need to reduce the depth of the pipeline or optimize stages to minimize delays, even if it sacrifices some throughput.
Key Considerations:
- Maximize throughput when high data processing rates are required, but ensure latency remains within acceptable limits for the specific application.
- Balance latency and throughput according to the performance goals of your system. In some cases, hybrid designs that combine both pipelined and non-pipelined paths can be effective.
2. Data Dependencies and Hazard Handling
Data dependencies, or hazards, arise when one pipeline stage depends on the output of another stage. These hazards can lead to incorrect data processing or require additional hardware to manage them. The three main types of hazards are:
- Structural hazards, where multiple pipeline stages need the same hardware resource.
- Data hazards, where an instruction depends on the result of a previous instruction.
- Control hazards, which occur during branching or conditional logic.
Techniques for Managing Hazards:
- Interlocks: Insert wait states in the pipeline to handle data dependencies. While this can ensure correct results, it introduces pipeline stalls that reduce throughput.
- Forwarding (bypassing): Use hardware to forward the result from a later pipeline stage to an earlier stage that needs it. This technique reduces stalls and improves performance but requires additional routing and complexity.
- Speculation: For control hazards, speculative execution allows the pipeline to guess the outcome of a branch and continue execution, reverting if the guess is incorrect. Speculation can enhance throughput but also introduces risks of wasted cycles if the prediction fails.
When designing FPGA pipelines, addressing these hazards efficiently is crucial to maintaining high performance. Engineers must assess whether the added complexity of hazard management mechanisms (e.g., forwarding logic) is justified by the performance gains.
3. Clock Speed and Pipeline Depth
The speed at which data flows through the pipeline is determined by the clock frequency, and the depth of the pipeline influences the number of clock cycles required to process a single data element. One of the major challenges in FPGA design is finding the right balance between clock speed and pipeline depth.
Increasing the depth of the pipeline (i.e., breaking the operation into more stages) can allow each stage to be simpler and faster, potentially increasing the maximum clock frequency. However, deeper pipelines also result in higher overall latency and require careful attention to data synchronization across stages.
Key Considerations:
- Critical path analysis: Identify the longest path through the circuit that limits the maximum clock frequency. Optimizing the pipeline stages to shorten this critical path can improve the overall performance.
- Clock domain crossing: If your FPGA design uses multiple clock domains, ensure that data is correctly synchronized between them. Improper handling of clock domain crossings can lead to data corruption or timing violations.
- Balancing stage complexity: Avoid stages that are either too complex (slowing down the pipeline) or too simple (resulting in under-utilized hardware). Finding the right level of granularity for each pipeline stage is critical.
4. Resource Utilization: Efficient Use of FPGA Resources
FPGAs offer a wide range of configurable resources, including logic cells, block RAM (BRAM), Digital Signal Processing (DSP) blocks, and I/O pins. An efficient pipeline design must make optimal use of these resources to achieve high performance without exceeding the device’s capacity.
Key Resources:
- Logic Cells: The primary resource used for combinatorial logic and routing. Efficient pipeline designs should minimize logic cell usage by optimizing the complexity of each stage.
- Block RAM: Used to store intermediate results, lookup tables, or buffers between pipeline stages. Efficient use of BRAM can reduce the need for external memory access, improving performance and reducing latency.
- DSP Blocks: Specialized blocks for arithmetic operations such as multiplication and addition. Pipelines that involve heavy mathematical computations, such as digital filters, can leverage DSP blocks to offload work from the general logic fabric, improving efficiency.
Optimization Strategies:
- Register Balancing: Ensure that registers are distributed evenly across the pipeline to prevent bottlenecks. This can also help reduce routing congestion and improve timing closure.
- Parallelism: Exploit the inherent parallelism of FPGAs by duplicating resources when necessary, allowing multiple pipeline stages to execute simultaneously.
- Resource Sharing: For operations that are not performance-critical, consider sharing hardware resources across multiple stages or tasks to conserve FPGA resources.
5. Managing Memory in Pipelined Designs
Efficient memory management is critical in FPGA pipelines, especially when dealing with large datasets or frequent memory accesses. Poorly designed memory architectures can lead to bottlenecks that degrade the performance of an otherwise well-optimized pipeline.
Memory Considerations:
- On-chip vs. Off-chip Memory: On-chip memory, such as block RAM (BRAM), is faster and can be accessed more efficiently than off-chip memory (e.g., DRAM). Use on-chip memory for frequently accessed data or intermediate results that require low-latency access. Off-chip memory should be reserved for larger datasets that don’t fit within the FPGA’s BRAM.
- Memory Bandwidth: Ensure that your pipeline design doesn’t exceed the available memory bandwidth. If multiple pipeline stages need access to the same memory, you may need to implement memory partitioning, banking, or double-buffering to avoid conflicts and ensure high throughput.
- FIFO Buffers: First-in, first-out (FIFO) buffers are often used between pipeline stages to handle variable data rates or to decouple stages. Proper sizing and placement of FIFO buffers are essential to prevent data loss or pipeline stalls.
6. Verification and Debugging of Pipelined Designs
Verification of FPGA pipeline designs can be particularly challenging due to the parallel and timing-sensitive nature of the hardware. Traditional software debugging techniques are often insufficient, and specialized methods must be employed.
Debugging Techniques:
- Simulation: Simulate the pipeline design using hardware description language (HDL) simulators (e.g., ModelSim, Vivado) to verify functionality before deploying the design on the FPGA. Simulation allows for cycle-accurate debugging of timing and data flow.
- In-circuit Debugging: Once the design is running on the FPGA, in-circuit debugging tools such as Integrated Logic Analyzers (ILA) or Signal Tap can capture real-time signals and data from the FPGA, helping identify issues such as timing violations or incorrect data propagation.
- Testbenches: Create comprehensive testbenches that cover all possible input conditions and edge cases. Automated testbenches can significantly reduce the time required for verification and improve the robustness of the design.
7. Power Consumption in Pipelined Designs
Power consumption is an increasingly important consideration in FPGA design, particularly for applications in portable devices, edge computing, or other power-constrained environments. Pipelining can influence power consumption in several ways.
While pipelining can increase clock frequency and throughput, it also increases the number of active elements (registers, logic, etc.), which can lead to higher dynamic power consumption. Designers need to find a balance between performance and power efficiency.
Power Optimization Techniques:
- Clock Gating: Disable the clock to certain pipeline stages when they are not in use to save power.
- Power-Aware Synthesis: Use power-aware synthesis tools that automatically optimize the design for low power during synthesis and place-and-route processes.
- Voltage Scaling: In applications where performance can be traded off for power savings, consider using dynamic voltage scaling (DVS) to reduce the supply voltage for certain regions of the FPGA.
8. Case Study: Pipelining in Digital Signal Processing (DSP)
To illustrate the concepts discussed above, consider a common FPGA application: a digital signal processing (DSP) pipeline used for filtering and transforming input signals. In this example, we’ll examine how pipelining is applied to improve throughput while balancing resource utilization and power consumption.
Problem:
A DSP system is required to filter a high-frequency signal in real time, processing a continuous stream of data. Without pipelining, the filtering operation would involve multiple sequential stages (e.g., multiplication, addition, shifting), leading to a bottleneck in processing speed.
Solution:
By introducing a pipeline, each filtering operation is broken down into multiple stages:
- Stage 1: Input data is fetched and multiplied by the filter coefficients.
- Stage 2: The products are summed to produce the filter output.
- Stage 3: The output is stored and passed to the next stage of the system.
Results:
The pipelined design allows each stage to execute in parallel, resulting in continuous, high-speed filtering with minimal delay between inputs. By carefully balancing the pipeline stages and leveraging FPGA resources like DSP blocks for multiplication, the design achieves high throughput with low resource usage and power consumption.
Conclusion
Pipelining is a powerful technique for improving the performance of FPGA designs, but implementing efficient pipelines requires careful consideration of factors such as latency, throughput, resource utilization, memory management, and power consumption. By balancing these factors and leveraging the unique capabilities of FPGAs, engineers can design pipelines that deliver optimal performance for a wide range of applications.
Whether you’re designing DSP filters, image processing systems, or complex control algorithms, the principles discussed in this article provide a foundation for creating high-performance, efficient FPGA pipelines.







