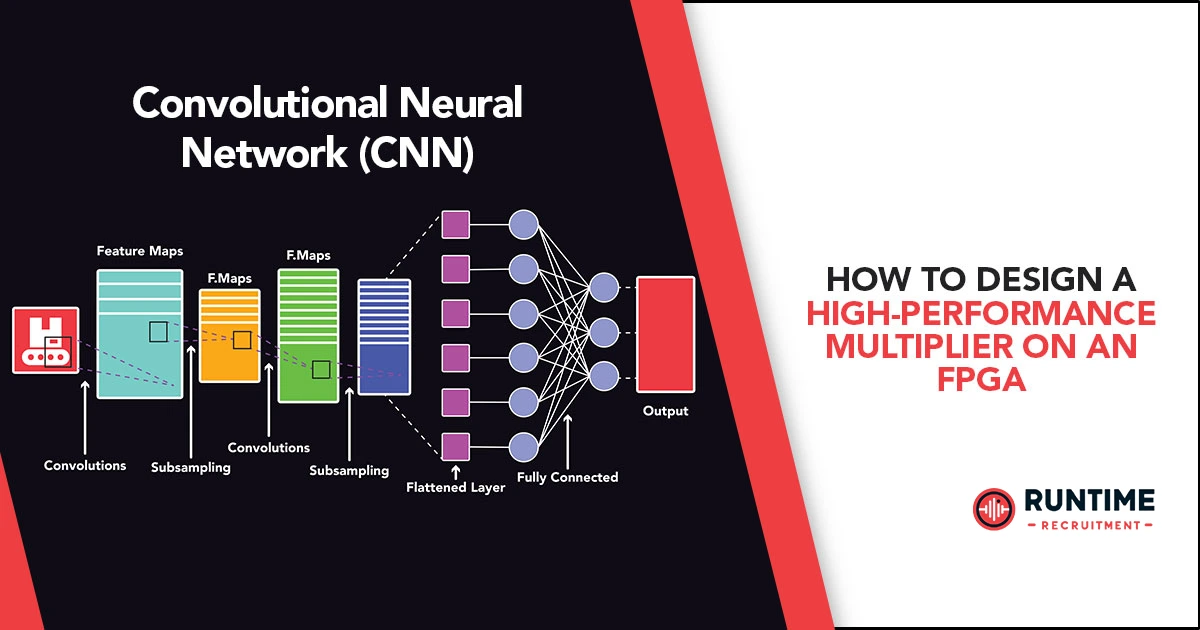
Introduction
The intersection of deep learning and hardware acceleration has ushered in a new era of computational efficiency. Among the hardware platforms that have gained prominence, Field Programmable Gate Arrays (FPGAs) stand out for their flexibility and performance potential. This article delves into the intricacies of designing a Convolutional Neural Network (CNN) on an FPGA, emphasizing technical depth, innovation, and practical considerations.
Understanding the Challenge
Before diving into the design process, it’s crucial to appreciate the unique challenges and opportunities presented by FPGAs. While they offer unparalleled parallelism and low latency, they also come with constraints in terms of resource utilization and power consumption. CNNs, on the other hand, are computationally intensive, demanding high throughput and precision.
FPGAs are integrated circuits that can be programmed after manufacturing to implement various logical functions. They consist of an array of programmable logic blocks and a hierarchy of reconfigurable interconnects, enabling customization for specific computational tasks. The flexibility of FPGAs makes them ideal for accelerating deep learning algorithms, particularly CNNs.
Key Design Considerations
CNN Architecture Selection
The choice of CNN architecture is heavily influenced by the specific application. For image classification, architectures like AlexNet, VGG, or ResNet might be suitable, while object detection tasks often benefit from YOLO or SSD. Here are key considerations when selecting a CNN architecture for FPGA implementation:
- Identify the Target Application: The target application dictates the requirements for accuracy, throughput, and latency. For instance, real-time video processing demands low latency, while medical image analysis might prioritize high accuracy.
- Quantization: To reduce resource utilization and improve performance, consider quantizing weights and activations to lower bit widths. Quantization reduces the number of bits used to represent each parameter, thus saving memory and computational resources. However, careful evaluation is necessary to assess the impact on accuracy. Techniques such as 8-bit or even 4-bit quantization are commonly used.
- Hardware-Friendly Layers: Opt for CNN architectures with layers that map efficiently to FPGA hardware. For instance, depthwise separable convolutions, common in mobile-friendly architectures, can be implemented efficiently on FPGAs. These layers reduce the number of parameters and computations, making them suitable for hardware acceleration.
Hardware Implementation
- Dataflow vs. Control Flow: Decide between a dataflow or control flow approach based on the desired level of parallelism and resource utilization. Dataflow architectures often excel in throughput, while control flow designs offer more flexibility. In a dataflow architecture, computation units are directly connected, allowing data to flow continuously. This can lead to higher throughput but requires careful design to avoid bottlenecks.
- Memory Hierarchy: Efficient memory access is critical for CNN performance. Design a memory hierarchy that balances on-chip and off-chip memory usage, considering data locality and access patterns. On-chip memory, such as block RAM, offers low latency but limited capacity, while off-chip memory, like DDR, provides higher capacity but with higher latency.
- Pipeline Optimization: Employ pipelining to maximize throughput by overlapping computation stages. Pipelining involves breaking down the computation into stages and processing multiple data elements simultaneously at different stages. Careful analysis of data dependencies is essential to identify pipelining opportunities.
- Custom Arithmetic Units: For performance-critical operations like convolution, consider designing custom arithmetic units to optimize for speed and resource efficiency. Custom units can be tailored to the specific bit-width and precision requirements of the CNN, providing significant performance gains.
FPGA Resource Utilization
- Hardware/Software Partitioning: Determine which parts of the CNN should be implemented in hardware and which can be offloaded to the host CPU. This decision depends on factors such as performance requirements, resource constraints, and development efforts. Commonly, compute-intensive layers like convolutions are implemented in hardware, while less demanding operations like activation functions can run on the CPU.
- High-Level Synthesis (HLS): Utilize HLS tools to accelerate the design process and improve resource utilization. HLS allows you to write C/C++ code that is automatically synthesized into hardware. This approach simplifies the development process and enables faster iterations compared to traditional hardware description languages (HDLs) like VHDL or Verilog.
- Floorplanning and Placement: Optimize the physical layout of the design to minimize wire length and improve timing closure. Efficient floorplanning and placement ensure that critical paths are short and meet timing requirements, leading to higher operating frequencies.
Performance Evaluation and Optimization
- Benchmarking: Thoroughly evaluate the performance of the FPGA-accelerated CNN using relevant benchmarks and metrics. Common metrics include throughput (inferences per second), latency (time per inference), and resource utilization (LUTs, DSPs, BRAMs).
- Power Analysis: Assess power consumption to identify optimization opportunities and ensure compliance with power budgets. FPGAs are known for their high power efficiency compared to general-purpose processors, but careful design is needed to minimize power consumption.
- Iterative Refinement: Continuously refine the design based on performance measurements and analysis. Use profiling tools to identify bottlenecks and optimize critical sections of the design. Iterative refinement is key to achieving optimal performance.
Advanced Techniques
Dynamic Partial Reconfiguration
Explore the potential of dynamic partial reconfiguration to adapt the FPGA to different CNN models or operating conditions. This technique allows for reconfiguring parts of the FPGA on the fly without stopping the entire system, enabling more efficient use of resources.
Approximate Computing
Investigate the use of approximate computing techniques to trade off accuracy for improved performance and energy efficiency. Techniques like reduced precision arithmetic, approximate multipliers, and speculative execution can significantly boost performance while maintaining acceptable accuracy levels.
Emerging FPGA Technologies
Stay updated on emerging FPGA technologies, such as 3D integration and specialized hardware accelerators, to leverage the latest advancements. Technologies like High Bandwidth Memory (HBM) and domain-specific accelerators offer new possibilities for enhancing CNN performance on FPGAs.
Practical Implementation
Define Requirements
Start by defining the performance, accuracy, and power requirements for your target application. This will guide your architecture selection, quantization strategies, and overall design approach.
Select Tools and Frameworks
Choose appropriate tools and frameworks for your development process. High-Level Synthesis (HLS) tools like Xilinx Vivado HLS or Intel’s HLS Compiler can accelerate development by allowing you to describe your design in high-level languages like C or C++. Additionally, frameworks like Vitis AI can help in optimizing and deploying deep learning models on FPGAs.
Model Quantization
Quantize your CNN model to reduce resource utilization and improve performance. Use tools like TensorFlow Lite or PyTorch’s quantization library to convert your model’s weights and activations to lower bit-width representations.
Hardware Mapping
Map your CNN layers to FPGA resources. Focus on implementing compute-intensive layers such as convolutions in hardware, while less demanding operations like activation functions and pooling can be handled by the CPU.
Design Custom Arithmetic Units
For critical operations, design custom arithmetic units tailored to the specific requirements of your CNN. This may involve creating custom multipliers, adders, and other arithmetic blocks optimized for the bit-width and precision of your quantized model.
Optimize Memory Hierarchy
Design an efficient memory hierarchy that balances on-chip and off-chip memory usage. Implement double-buffering and loop unrolling techniques to maximize data throughput and minimize latency.
Implement Pipelining
Employ pipelining to increase throughput. Break down the CNN computations into multiple stages and process data elements in parallel. This requires careful analysis to identify dependencies and potential bottlenecks.
Perform Floorplanning and Placement
Optimize the physical layout of your design on the FPGA to minimize wire lengths and improve timing closure. Use tools like Xilinx Vivado or Intel Quartus Prime to assist with floorplanning and placement.
Benchmark and Refine
Thoroughly benchmark your FPGA-accelerated CNN using relevant metrics such as throughput, latency, and power consumption. Use profiling tools to identify bottlenecks and areas for optimization. Iterate your design based on the benchmark results to achieve the desired performance.
Validate and Deploy
Validate your design on real hardware to ensure it meets the performance, accuracy, and power requirements. Once validated, deploy your FPGA-accelerated CNN in the target environment, whether it be for real-time video processing, medical image analysis, or other applications.
Overview of YOLO
YOLO is a popular object detection algorithm known for its high speed and accuracy. It frames object detection as a single regression problem, directly predicting bounding boxes and class probabilities from full images in one evaluation. This makes YOLO particularly well-suited for real-time applications.
Implementation
Define Requirements
For this case study, the requirements are as follows:
- Real-time performance: Minimum 30 frames per second (fps) for video processing.
- Accuracy: Comparable to the original YOLO implementation.
- Power efficiency: Optimized for deployment on edge devices.
Select Tools and Frameworks
Use Xilinx Vivado HLS for high-level synthesis and Vitis AI for optimizing and deploying the YOLO model on the FPGA.
Model Quantization
Quantize the YOLO model to 8-bit precision for weights and activations using TensorFlow Lite’s quantization tools. This significantly reduces resource utilization and improves performance without substantial loss in accuracy.
Hardware Mapping
Map the compute-intensive convolutional layers of the YOLO model to FPGA resources. The remaining layers, such as activation functions and pooling layers, can be handled by the CPU.
Design Custom Arithmetic Units
Design custom arithmetic units for convolution operations, optimized for 8-bit precision. These custom units include multipliers and adders specifically tailored for the quantized YOLO model.
Optimize Memory Hierarchy
Implement a double-buffering scheme to ensure continuous data flow between the FPGA and memory. This reduces latency and maximizes data throughput.
Implement Pipelining
Pipeline the convolutional layers to process multiple frames in parallel. This involves breaking down the computation into smaller stages and processing different parts of the image simultaneously.
Perform Floorplanning and Placement
Use Xilinx Vivado’s floorplanning and placement tools to optimize the physical layout of the design on the FPGA. This step ensures that critical paths are minimized, and timing requirements are met.
Benchmark and Refine
Benchmark the FPGA-accelerated YOLO model using relevant metrics such as fps, latency, and power consumption. Use profiling tools to identify bottlenecks and optimize the design. Iterate on the design based on benchmark results to achieve the desired performance.
Validate and Deploy
Validate the design on real hardware by processing video streams and verifying the accuracy and performance of the object detection system. Once validated, deploy the FPGA-accelerated YOLO model on edge devices for real-time object detection.
Conclusion
Designing a CNN on an FPGA requires a deep understanding of both hardware and software concepts. By carefully considering the factors outlined in this article, engineers can develop efficient and high-performance FPGA-based CNN accelerators. The journey from algorithm to hardware is challenging but rewarding, offering the potential for significant performance gains and energy savings.
Hire the Best Engineers with RunTime
At RunTime, we are dedicated to helping you find the best Engineering talent for your recruitment needs. Our team consists of engineers-turned-recruiters with an extensive network and a focus on quality. By partnering with us, you will have access to great engineering talent that drives innovation and excellence in your projects.
Discover how RunTime has helped 423+ tech companies find highly qualified and talented engineers to enhance their team’s capabilities and achieve strategic goals.
On the other hand, if you’re a control systems engineer looking for new opportunities, RunTime Recruitment’s job site is the perfect place to find job vacancies.







