In the intricate world of embedded systems, where every byte counts and every operation is critical, ensuring data integrity is paramount. From pacemakers to spacecraft, autonomous vehicles to industrial control systems, the silent killer of memory corruption poses a constant threat. A single flipped bit, an errant write, or a transient hardware fault can lead to catastrophic failures, making real-time detection of such anomalies not just desirable, but absolutely essential. This is where CRC shadow checking emerges as a powerful, yet often underutilized, technique.
The Invisible Enemy: Understanding Memory Corruption
Before delving into the elegance of CRC shadow checking, it’s crucial to grasp the nature of the adversary: memory corruption. Unlike software bugs that might manifest as logical errors, memory corruption is a physical or logical alteration of data stored in memory that deviates from its intended value. These alterations can be caused by a multitude of factors:
- Hardware Faults:
- Single Event Upsets (SEUs): These are transient errors caused by cosmic rays or alpha particles striking memory cells, flipping a bit. While often non-destructive to the hardware itself, the data corruption can be devastating.
- Electromagnetic Interference (EMI): External electromagnetic fields can induce currents in memory traces, leading to bit flips.
- Power Fluctuations: Spikes or dips in power supply can cause unstable memory states.
- Aging Hardware: Over time, memory cells can degrade, becoming more susceptible to errors.
- Manufacturing Defects: Imperfections in the silicon or packaging can lead to unreliable memory operation.
- Software Bugs:
- Pointer Errors: Dereferencing null pointers, using wild pointers, or off-by-one errors in array indexing can lead to writes to unintended memory locations.
- Buffer Overflows/Underflows: Writing beyond the allocated bounds of a buffer can overwrite adjacent memory.
- Stack Overflows: Recursive functions or large local variables can consume excessive stack space, overwriting other data or return addresses.
- Uninitialized Variables: Using variables before they have been assigned a value can lead to unpredictable behavior, especially if the memory location contains remnants of previous data.
- Race Conditions: In multi-threaded environments, improper synchronization can lead to multiple threads accessing and modifying the same memory location simultaneously, resulting in corrupted data.
- Memory Leaks: While not directly memory corruption, unmanaged memory leaks can exhaust available memory, eventually leading to system instability and potentially unexpected memory behavior if the system attempts to allocate memory that is no longer truly available.
- External Factors:
- Vibration and Shock: In harsh environments, physical stress can cause solder joint failures or even microscopic cracks in memory chips, leading to intermittent contact.
- Temperature Extremes: Operating memory outside its specified temperature range can affect its reliability and data retention.
The insidious nature of memory corruption lies in its often silent arrival. A corrupted data point might go unnoticed for cycles, leading to accumulating errors or, worse, triggering a critical failure at the most inopportune moment. Traditional debugging techniques often struggle to pinpoint these transient or intermittent issues, making proactive detection mechanisms indispensable.
The Role of Checksums and CRCs
To combat data corruption, various error detection codes have been developed. Checksums, a simple form of error detection, involve summing the bytes of a data block. While easy to implement, they are not robust against certain types of errors (e.g., swapping two bytes will result in the same checksum).
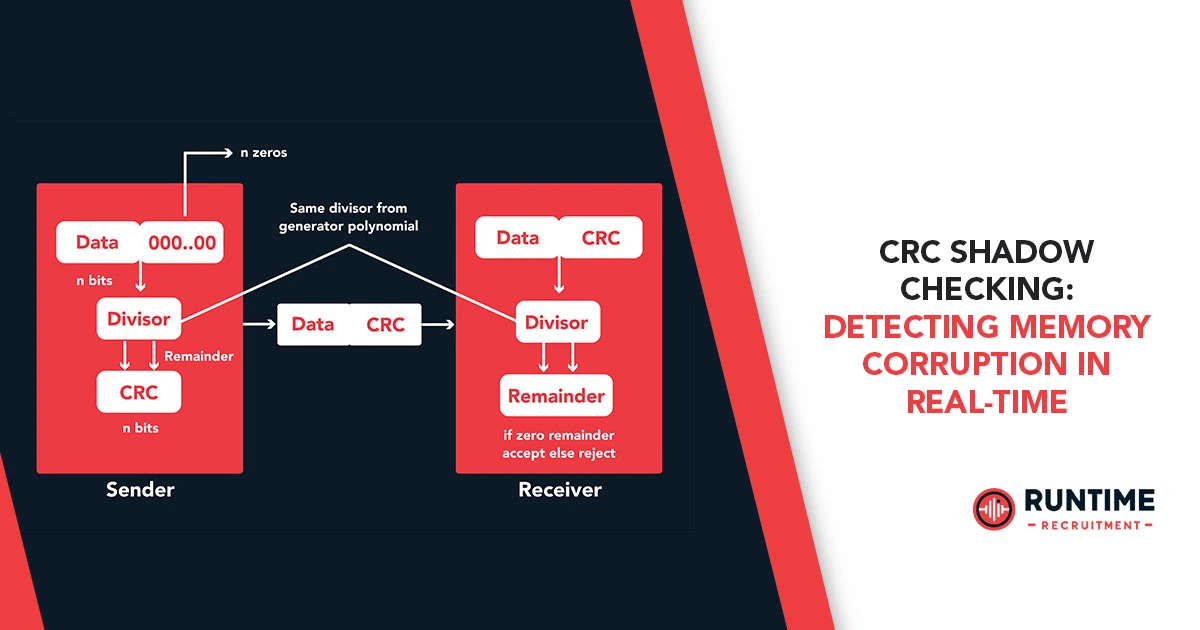
Cyclic Redundancy Checks (CRCs) offer a significantly more powerful and reliable solution. CRCs are a family of error-detecting codes used to detect accidental changes to raw data. They work by performing a polynomial division on the data message. The remainder of this division is the CRC, which is then appended to the data. When the data is received or read, the same polynomial division is performed. If the new remainder matches the appended CRC, the data is considered intact. Different CRC standards (e.g., CRC-8, CRC-16, CRC-32) offer varying levels of error detection capability, with higher-order CRCs providing greater protection against more complex error patterns.
Introducing CRC Shadow Checking
CRC shadow checking takes the power of CRCs and applies it in a continuous, real-time monitoring fashion. The core principle is deceptively simple yet profoundly effective:
- Baseline CRC Generation: At a known good state (e.g., system initialization, a stable operational phase, or after a critical data write), a CRC is calculated for a specific region of memory. This CRC becomes the “shadow” or reference.
- Continuous Monitoring (Shadow CRC Calculation): Periodically, or at critical junctures, a new CRC is calculated for the same memory region.
- Comparison and Detection: The newly calculated CRC is compared against the stored “shadow” CRC. If they do not match, it indicates that the memory region has been altered, signaling potential memory corruption.
The “shadow” aspect refers to the idea of having a parallel, hidden, and continuously updated check on the integrity of your critical data. It’s a vigilant sentry, constantly comparing the current state to a known good state.
Implementing CRC Shadow Checking: Practical Considerations
Implementing CRC shadow checking effectively requires careful consideration of several factors:
- Memory Region Selection:
- Critical Data Structures: Variables that hold critical system states, configuration parameters, lookup tables, or safety-critical values are prime candidates.
- Code Sections: While often residing in read-only memory (ROM/Flash), sections of RAM that contain loaded code (e.g., for self-modifying code or dynamically loaded modules) can also benefit from shadow checking.
- Stack and Heap: While challenging due to their dynamic nature, specific, less volatile sections of the stack or heap that hold persistent data could theoretically be monitored. However, the overhead might be prohibitive for highly dynamic areas.
- Shared Memory: In multi-core or multi-processor systems, shared memory regions are particularly vulnerable to corruption and are excellent candidates for shadow checking.
- CRC Algorithm Choice: The choice of CRC algorithm (CRC-8, CRC-16, CRC-32, etc.) depends on the desired level of error detection and the computational resources available. CRC-32 offers strong protection but requires more computational cycles than CRC-8. Consider the types of errors you are most concerned about.
- Checking Frequency:
- Periodic Polling: The simplest approach is to calculate the shadow CRC at fixed time intervals (e.g., every 10ms, 100ms). The frequency will depend on the criticality of the data and the acceptable latency for detection.
- Event-Driven: Trigger CRC recalculation after specific events, such as:
- After a critical data write operation.
- Before using a critical data value in a calculation or decision.
- During idle CPU cycles.
- Upon context switches in RTOS environments, for task-specific data.
- Handling Corruption Detection:
- Immediate Action: For safety-critical systems, detecting corruption might necessitate immediate system shutdown, entering a fail-safe state, or initiating a watchdog timer reset.
- Logging and Reporting: For less critical systems, logging the event and reporting it to a higher-level system can be sufficient for debugging and diagnostics.
- Data Correction (Limited Cases): While CRC shadow checking is primarily for detection, in some very specific scenarios (e.g., where the type of error can be inferred, and redundant data exists), a limited form of correction might be attempted. However, this adds significant complexity and is not the primary purpose of this technique.
- Computational Overhead: Calculating CRCs, especially for large memory regions, consumes CPU cycles. This overhead must be carefully considered during system design, particularly for resource-constrained embedded systems. Optimize CRC calculations by using hardware CRC accelerators (if available on the microcontroller) or highly optimized software implementations.
- Memory Overhead: Storing the “shadow” CRC itself requires a small amount of memory. This is typically negligible compared to the protected memory region.
- False Positives: Ensure that legitimate changes to the protected memory region are properly handled. If a region is truly updated, the “shadow” CRC must be re-calculated and stored. Failure to do so will result in false alarms. This is perhaps the most crucial aspect: the shadow CRC must always reflect the intended state of the data.
- Protection Against Malicious Attacks: While effective against accidental corruption, CRC shadow checking alone is not a robust defense against sophisticated malicious attacks that might intentionally tamper with both the data and its CRC. For such threats, cryptographic hashes and secure boot mechanisms are necessary.
Use Cases and Scenarios
Let’s explore some concrete examples of where CRC shadow checking can be invaluable:
- Avionics and Automotive:
- Flight Control Systems: Monitoring critical sensor data, actuator commands, and control algorithms. A corrupted input or output can have catastrophic consequences.
- Engine Control Units (ECUs): Protecting fuel injection maps, ignition timing parameters, and sensor readings.
- Autonomous Driving Systems: Ensuring the integrity of perception data, path planning algorithms, and vehicle control commands.
- Medical Devices:
- Implantable Devices (Pacemakers, Insulin Pumps): Verifying the integrity of pacing parameters, drug delivery dosages, and patient data. A single error could be life-threatening.
- Diagnostic Equipment: Ensuring the accuracy of calibration data and measurement results.
- Industrial Control Systems (ICS/SCADA):
- PLCs and RTUs: Protecting control logic, setpoints, and process variable readings. Incorrect values can lead to equipment damage or unsafe operating conditions.
- Robotics: Verifying joint positions, motor commands, and safety interlock states.
- Consumer Electronics (High Reliability):
- High-End Storage Devices: Ensuring data integrity on SSDs or complex RAID controllers.
- Smart Home Devices (Critical Functions): Though less common, for devices managing power or critical security, it could be a consideration.
- Space Applications:
- Satellite Onboard Computers: Protecting against cosmic ray-induced SEUs in memory used for attitude control, communication, and scientific instruments. Space is a prime example where transient errors are a major concern.
- Mars Rovers: Ensuring the integrity of navigation data, scientific measurements, and operational commands in an unforgiving environment.
Advantages of CRC Shadow Checking:
- Real-Time Detection: Provides immediate feedback on memory corruption, allowing for prompt corrective action.
- Lightweight: Compared to full memory scrubbing or ECC (Error Correcting Code) hardware (which corrects errors, not just detects), software-based CRC shadow checking can be relatively lightweight in terms of hardware requirements.
- Versatile: Can be applied to various memory regions and data types.
- Complementary: Can be used in conjunction with other error detection/correction mechanisms (e.g., ECC RAM, watchdog timers) to provide a layered defense.
- Early Warning System: Catches errors before they propagate and cause larger system failures.
- Cost-Effective: Often involves software changes and minimal to no hardware modifications, making it an attractive option for existing designs.
Limitations and Considerations:
- Computational Overhead: As mentioned, CRC calculation consumes CPU cycles. This is a primary trade-off to consider.
- No Correction: CRC shadow checking detects errors; it does not correct them. Further mechanisms are needed for recovery.
- Latency: The detection latency is directly tied to the checking frequency. More frequent checks mean lower latency but higher overhead.
- Protected Region Management: Requires careful management of when the “shadow” CRC needs to be updated to avoid false positives.
- Dynamic Memory: Challenging to apply effectively to highly dynamic memory regions like the heap without significant overhead or complex tracking.
- Boot-up Integrity: While great for runtime, it doesn’t protect against corruption of the boot image itself before the system is fully operational. Secure boot and image integrity checks are needed for this.
Best Practices for Implementation:
- Define Critical Regions: Clearly identify which memory sections are critical and warrant shadow checking.
- Optimize CRC Calculation:
- Utilize hardware CRC accelerators if available on your microcontroller.
- Implement highly optimized software CRC functions (e.g., lookup table-based implementations).
- Perform calculations in background tasks or during idle CPU cycles.
- Strategic Checking Frequency: Balance detection latency with computational overhead. Prioritize more frequent checks for the most critical data.
- Robust Error Handling: Define clear and tested responses to detected corruption (e.g., log, alert, reset, fail-safe).
- Initialize Shadow CRCs: Ensure the initial shadow CRC is calculated and stored at a known good state (e.g., after system power-up and data initialization).
- Update Shadow CRCs Correctly: Crucially, whenever the protected memory region is legitimately modified, the corresponding shadow CRC must be recalculated and updated. This is where most implementation errors occur, leading to false positives.
- Consider Memory Alignment: For optimal performance, ensure that memory regions are aligned in a way that is efficient for your chosen CRC algorithm and processor architecture.
- Thorough Testing: Rigorously test the shadow checking mechanism under various scenarios, including simulated memory errors, to validate its effectiveness and ensure false positives are minimized.
- Documentation: Clearly document the protected memory regions, CRC algorithms used, checking frequencies, and the system’s response to detected corruption.
Conclusion
In the demanding landscape of embedded systems, memory corruption remains a persistent and potentially devastating threat. CRC shadow checking offers embedded engineers a powerful, practical, and often essential tool for real-time detection of these insidious errors. By strategically applying this technique to critical memory regions, development teams can significantly enhance the reliability, robustness, and safety of their embedded systems. While not a silver bullet, when intelligently implemented and combined with other robust design practices, CRC shadow checking provides a vital layer of defense, giving engineers greater confidence in the integrity of their data and the uninterrupted operation of their mission-critical applications. As embedded systems become ever more complex and ubiquitous, embracing such vigilant mechanisms will be key to building the trustworthy and resilient technologies of tomorrow.







