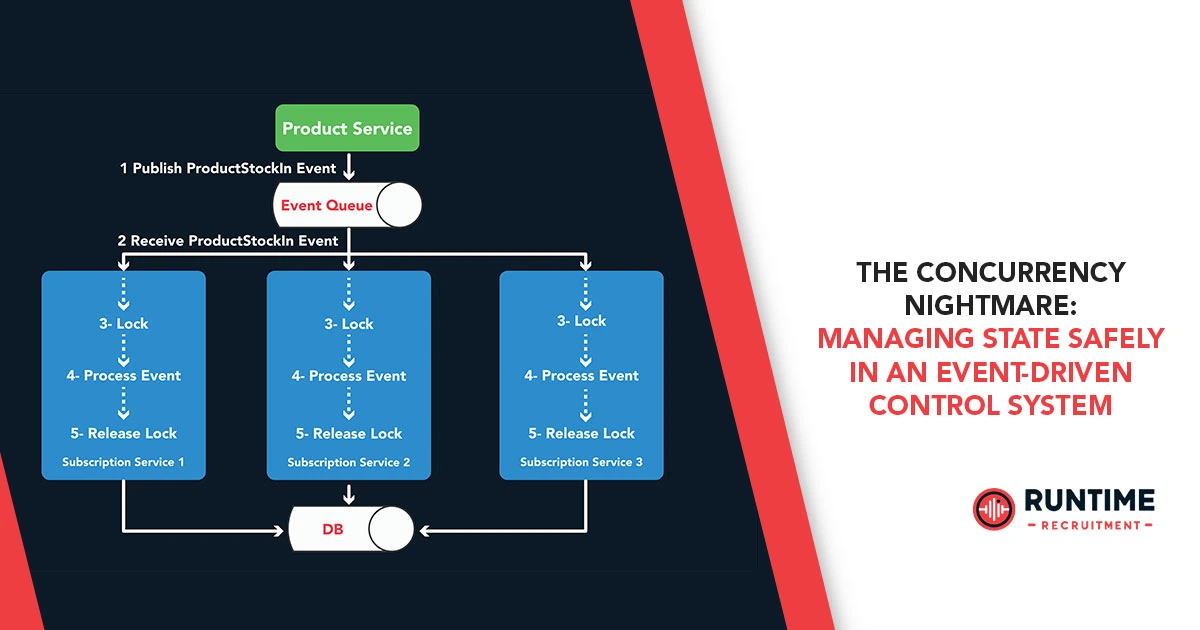
Embedded systems are undergoing a quiet revolution. Gone are the days of simple, sequential loops processing sensor inputs and toggling actuators. Modern embedded control systems are increasingly sophisticated, driven by a deluge of asynchronous events, multiple independent tasks, and the imperative for real-time responsiveness. This evolution, while empowering, ushers in a formidable adversary: the concurrency nightmare.
At the heart of this nightmare lies the insidious challenge of managing shared state safely in an event-driven, multi-threaded or multi-tasking environment. When multiple execution contexts – be they threads, tasks, or interrupt service routines (ISRs) – can simultaneously read from and write to the same data, chaos ensues. Race conditions, deadlocks, livelocks, and data corruption are not just theoretical possibilities; they are the lurking demons that can turn a meticulously designed system into an unpredictable, unreliable, and potentially dangerous liability.
This article delves deep into the heart of this concurrency nightmare, dissecting the challenges, exploring common pitfalls, and providing a comprehensive guide to navigating the treacherous waters of state management in event-driven embedded control systems. We’ll examine the fundamental principles, practical strategies, and advanced techniques that embedded engineers can employ to build robust, safe, and predictable systems.
The Rise of Event-Driven Systems: A Double-Edged Sword
Event-driven architectures have become the de facto standard for many modern embedded systems, particularly those dealing with complex interactions and asynchronous inputs. Think about a smart home hub reacting to sensor data, a factory automation system responding to machine events, or an automotive ECU processing CAN messages and driver inputs. In these scenarios, the system’s behavior is dictated by external stimuli, not a pre-defined, sequential flow.
Benefits of Event-Driven Design:
- Responsiveness: Systems can react immediately to inputs, crucial for real-time applications.
- Modularity: Logic can be decoupled into handlers for specific events, improving maintainability.
- Flexibility: Easily adapt to new features by adding new event handlers.
- Efficiency: System resources can be allocated only when needed, avoiding busy-waiting.
However, these benefits come at a significant cost: inherent concurrency. When an event arrives, it often triggers an execution path that runs concurrently with other ongoing tasks or event handlers. If these concurrent paths touch shared data, the stage is set for a concurrency nightmare.
Understanding the Beasts: Race Conditions, Deadlocks, and Friends
Before we can manage state safely, we must understand the specific threats posed by concurrency.
- Race Conditions: This is the most common and arguably the most insidious beast. A race condition occurs when the correctness of a computation depends on the relative timing or interleaving of multiple independent operations.
- Example: Imagine a shared counter variable, motor_speed_command. One task reads sensor data and wants to increment it. Another task receives a user input and wants to decrement it. If both tasks try to modify motor_speed_command without proper synchronization, the final value could be incorrect.
- Task A reads motor_speed_command (let’s say 100).
- Task B reads motor_speed_command (also 100).
- Task A increments its local copy (101) and writes it back.
- Task B decrements its local copy (99) and writes it back.
- The final value is 99, even though the net effect should have been an increment and a decrement, leaving 100.
- Race conditions are notoriously difficult to debug because they are non-deterministic – they might only appear under specific, hard-to-reproduce timing conditions.
- Example: Imagine a shared counter variable, motor_speed_command. One task reads sensor data and wants to increment it. Another task receives a user input and wants to decrement it. If both tasks try to modify motor_speed_command without proper synchronization, the final value could be incorrect.
- Deadlocks: A deadlock occurs when two or more tasks are blocked indefinitely, waiting for each other to release a resource that they need.
- Example: Task A needs resource X and resource Y. Task B also needs resource X and resource Y.
- Task A acquires X.
- Task B acquires Y.
- Task A tries to acquire Y but is blocked because B holds it.
- Task B tries to acquire X but is blocked because A holds it.
- Both tasks are now stuck, waiting for the other, leading to system paralysis.
- Example: Task A needs resource X and resource Y. Task B also needs resource X and resource Y.
- Livelocks: Similar to deadlocks, tasks make progress but never complete their work. They continuously change their state in response to each other without making forward progress. Imagine two people politely trying to pass each other in a narrow hallway, constantly stepping aside for the other until they are both stuck in an endless loop of yielding.
- Priority Inversion: A particularly nasty problem in RTOS environments. A high-priority task gets blocked waiting for a resource that is held by a low-priority task, but the low-priority task is preempted by a medium-priority task. The high-priority task effectively gets held up by the medium-priority task, despite having higher priority. This can severely compromise real-time guarantees.
- Data Corruption: At its core, all these issues often lead to data corruption, where shared variables hold incorrect or inconsistent values, leading to unpredictable system behavior, erroneous control outputs, and potential system failures.
The State Management Challenge: Where is Your Data?
In an event-driven system, state is scattered. It’s in global variables, member variables of objects, hardware registers, and even within the contexts of different event handlers. The critical challenge is identifying what constitutes shared state and who has access to it.
Key Questions for State Identification:
- Global Variables: Any global variable accessible by multiple tasks/ISRs is shared state.
- Static Variables: Static variables within functions or objects can also be shared if multiple instances or execution contexts access them.
- Hardware Registers: Direct access to hardware registers (e.g., configuring a timer, reading an ADC) often involves shared state, as multiple parts of the system might need to interact with the same peripheral.
- Pointers: Shared pointers can lead to indirect sharing of data structures.
- Function Arguments: While function arguments are usually local copies, passing pointers or references means the underlying data is still shared.
A thorough understanding of your system’s data flow and dependencies is the first step towards taming the concurrency beast.
Taming the Beast: Strategies for Safe State Management
The good news is that embedded engineers have a powerful arsenal of tools and techniques to manage shared state safely. The choice of technique depends on the specific context, the nature of the shared data, and the real-time constraints of the system.
1. Mutual Exclusion: The Foundation
The most fundamental concept for protecting shared state is mutual exclusion, ensuring that only one task can access a critical section (a piece of code that accesses shared resources) at any given time.
- Semaphores (Binary & Counting):
- Binary Semaphores (Mutexes): Often used for mutual exclusion. A task “takes” the mutex before entering a critical section and “gives” it upon exit. If another task tries to take a mutex that is already taken, it blocks until the mutex is released. This guarantees that only one task is in the critical section at a time.
- RTOS Features: Most RTOSes provide mutexes with priority inheritance mechanisms to mitigate priority inversion.
- Usage: Protecting shared variables, data structures, or hardware access.
- Caution: Incorrect usage (e.g., forgetting to release a mutex, deadlock) can lead to system hangs.
- Counting Semaphores: Used to control access to a pool of resources (e.g., allowing only N tasks to use a printer).
- Usage: Resource management, signaling between tasks.
- Binary Semaphores (Mutexes): Often used for mutual exclusion. A task “takes” the mutex before entering a critical section and “gives” it upon exit. If another task tries to take a mutex that is already taken, it blocks until the mutex is released. This guarantees that only one task is in the critical section at a time.
- Interrupt Disabling:
- Mechanism: Temporarily disabling interrupts prevents any other code (including ISRs and other tasks that might be scheduled) from running, thereby ensuring exclusive access to a critical section.
- Usage: Very short critical sections, especially when interacting with hardware registers or variables shared with ISRs.
- Caution: Disabling interrupts for too long can lead to missed interrupts, violate real-time deadlines, and degrade system responsiveness. Use sparingly and only for very brief operations.
- Spinlocks:
- Mechanism: A task repeatedly checks a flag until it indicates that it can proceed, effectively “spinning” in a loop.
- Usage: Multi-core systems where the locked resource is expected to be available very quickly.
- Caution: In single-core systems, spinlocks are highly inefficient as they consume CPU cycles without doing useful work and can lead to priority inversion if not used carefully.
2. Data Transfer Mechanisms: Communicating Safely
Instead of directly sharing memory, often it’s safer to transfer data between tasks.
- Message Queues (Mailboxes):
- Mechanism: Tasks send messages (data packets) to a queue, and other tasks receive messages from the queue. The RTOS handles synchronization, blocking tasks if the queue is empty or full.
- Usage: Decoupling producers and consumers of data, command passing, event notification.
- Benefits: Reduces direct shared memory access, simplifies synchronization, provides buffering.
- Caution: Message copy overhead, potential for queue overflow if not sized correctly.
- Ring Buffers/Circular Buffers:
- Mechanism: A fixed-size buffer where data is written sequentially, wrapping around to the beginning when the end is reached. Read and write pointers manage access.
- Usage: High-throughput data streaming (e.g., ADC samples, UART receive data).
- Synchronization: Typically requires careful use of interrupts and memory barriers for single-producer, single-consumer scenarios, or mutexes/semaphores for multi-producer/multi-consumer.
- Benefits: Efficient use of memory, low overhead for single producer/consumer.
3. Atomic Operations: Small, Indivisible Changes
For simple operations on primitive data types, atomic operations provide a lightweight synchronization mechanism.
- Mechanism: These are operations (e.g., increment, decrement, read-modify-write) that are guaranteed to complete without interruption by other tasks or interrupts. Many modern microcontrollers provide hardware support for atomic operations.
- Usage: Updating flags, counters, or simple state variables.
- Benefits: Very low overhead, avoids the need for heavy synchronization primitives for simple cases.
- Caution: Only applicable to specific, often primitive, operations. Not suitable for complex data structures.
4. Event-Driven Patterns: Design for Concurrency
Beyond individual primitives, certain architectural patterns inherently improve concurrency safety.
- Active Objects/Actors:
- Mechanism: Each “object” (or actor) runs in its own thread or task and communicates with other active objects solely through message passing. An active object has its own event queue and internal state, which it manages exclusively.
- Benefits: Encapsulates state, removes shared memory access between active objects, inherently thread-safe at the inter-object level.
- Usage: Complex systems with many independent components.
- State Machines (FSMs):
- Mechanism: Defines system behavior as a set of states and transitions between them, triggered by events.
- Benefits: Can manage concurrency within a single task effectively by ensuring that state transitions are atomic and well-defined. Each state only processes relevant events.
- Usage: Most control systems, protocol stacks, UI logic.
- Concurrency Integration: A state machine can run within an active object, providing a powerful combination.
5. Advanced Techniques & Considerations
- Memory Barriers (Fences):
- Mechanism: Instructions that prevent the compiler and processor from reordering memory operations across the barrier. This is critical for ensuring data visibility, especially in multi-core systems or when interacting with volatile hardware.
- Usage: Low-level device drivers, lock-free algorithms.
- Lock-Free Programming:
- Mechanism: Designing algorithms that do not rely on locks (mutexes, semaphores) for synchronization. Often uses atomic operations and careful memory ordering.
- Benefits: Can offer higher performance and avoid deadlocks and priority inversion in specific scenarios.
- Caution: Extremely complex to implement correctly. Prone to subtle bugs if not rigorously designed and tested. Typically for expert-level concurrency engineers.
- Read-Write Locks:
- Mechanism: Allows multiple readers to access a resource concurrently, but only one writer at a time. A writer blocks all readers and other writers.
- Benefits: Improves parallelism for data that is read much more frequently than it is written.
- Usage: Caching systems, shared configuration data.
- Static Analysis and Formal Verification:
- Mechanism: Tools that analyze your code for potential concurrency issues (race conditions, deadlocks) without actually running it. Formal verification uses mathematical proofs to guarantee certain properties of the system.
- Benefits: Can catch subtle bugs early in the development cycle.
- Caution: Can be complex to set up and may have false positives. Formal verification is resource-intensive and often applied to safety-critical components.
Best Practices for Concurrency Safety
Even with the right tools, discipline is paramount.
- Minimize Shared State: The less data that needs to be shared, the fewer opportunities for concurrency issues. Refactor your design to encapsulate state where possible.
- Encapsulate Access: Never allow direct, unprotected access to shared state. All modifications and reads should go through protected functions or methods (e.g., getters/setters that acquire/release mutexes).
- Define Clear Ownership: For every piece of data, clearly define which task or module is its “owner” and is primarily responsible for its modification. Other tasks should interact through well-defined, synchronized interfaces.
- Keep Critical Sections Short: The shorter the duration that a mutex is held or interrupts are disabled, the less impact on system responsiveness and the lower the chance of creating contention.
- Consistent Locking Order: To prevent deadlocks, always acquire multiple locks in the same predetermined order across all tasks in your system.
- Avoid Blocking in ISRs: ISRs should be as short and fast as possible. Never use blocking RTOS calls (e.g., xSemaphoreTake()) within an ISR. Use non-blocking variants or defer complex processing to a task.
- Use RTOS-Provided Primitives: Leverage the battle-tested synchronization primitives provided by your RTOS (FreeRTOS, Zephyr, RTX, etc.). Don’t try to roll your own unless absolutely necessary and you know exactly what you’re doing.
- Thorough Testing: Concurrency bugs are notoriously difficult to reproduce. Employ stress testing, random task scheduling, and specific test cases designed to trigger race conditions. Instrument your code with assertions and logging.
- Consider Event-Driven Frameworks: For complex systems, consider using frameworks that inherently promote safe concurrency through patterns like Active Objects or hierarchical state machines (e.g., QP/C, µC/OS-III with message queues).
The Debugging Gauntlet: When the Nightmare Becomes Reality
Despite best efforts, concurrency bugs will inevitably rear their ugly heads. Debugging them is an art and a science.
- Logging: Detailed, timestamped logging of task switches, mutex acquisitions/releases, and variable changes can provide invaluable insights into the sequence of events leading to a bug.
- Debuggers with RTOS Awareness: Modern debuggers often have RTOS awareness, allowing you to inspect task states, queues, semaphores, and mutexes.
- Hardware Trace: Some microcontrollers offer hardware trace capabilities that can capture the exact sequence of instructions and data accesses, crucial for pinpointing race conditions.
- Memory Checkers: Tools that detect memory corruption, buffer overflows, and invalid memory accesses can help identify the root cause of data inconsistencies.
- Code Reviews: A fresh pair of eyes can often spot potential concurrency issues that the original developer overlooked.
Conclusion: Embracing Complexity with Confidence
The concurrency nightmare is a persistent challenge in event-driven embedded control systems, but it is not an insurmountable one. By understanding the underlying principles of concurrency, identifying potential pitfalls, and diligently applying proven strategies and tools, embedded engineers can build systems that are not only powerful and responsive but also robust, safe, and predictable.
The shift towards more complex, event-driven architectures demands a higher level of awareness and skill in managing shared state. It requires a thoughtful design process, rigorous implementation, and thorough testing. By embracing these challenges, we can confidently navigate the treacherous waters of concurrency and deliver the next generation of intelligent, reliable embedded solutions.
Ready to Navigate the Future of Embedded Systems?
The world of embedded engineering is constantly evolving, with concurrency management becoming an increasingly vital skill. If you’re looking for your next challenge in designing and implementing safe, high-performance embedded control systems, or if your team needs to find the best talent to conquer these complex problems, connect with RunTime Recruitment today. We specialize in pairing top embedded engineering talent with innovative companies pushing the boundaries of technology. Let’s build the future, safely.







