For embedded engineers, Field-Programmable Gate Arrays (FPGAs) represent a powerful paradigm for accelerating compute-intensive applications. Their inherent parallelism and reconfigurability offer unparalleled opportunities for custom hardware design, enabling substantial performance and energy efficiency gains over traditional processors. However, as processing capabilities on FPGAs continue to skyrocket, a familiar nemesis looms large: the “memory wall.” This pervasive bottleneck, where the speed of computation far outstrips the rate at which data can be accessed from memory, is a critical challenge that threatens to undermine the very advantages FPGAs promise.
The memory wall isn’t a new phenomenon in computing, but its manifestation in FPGAs presents unique complexities. Unlike CPUs with sophisticated cache hierarchies and robust memory controllers, FPGAs often rely on more direct, application-specific data movement strategies. The sheer flexibility that makes FPGAs so attractive can also lead to highly fragmented and inefficient data access patterns if not meticulously managed. This article delves deep into novel approaches for on-chip data movement, exploring how embedded engineers can strategically design their FPGA systems to mitigate the memory wall and unlock the full potential of these powerful devices.
Understanding the FPGA Memory Landscape
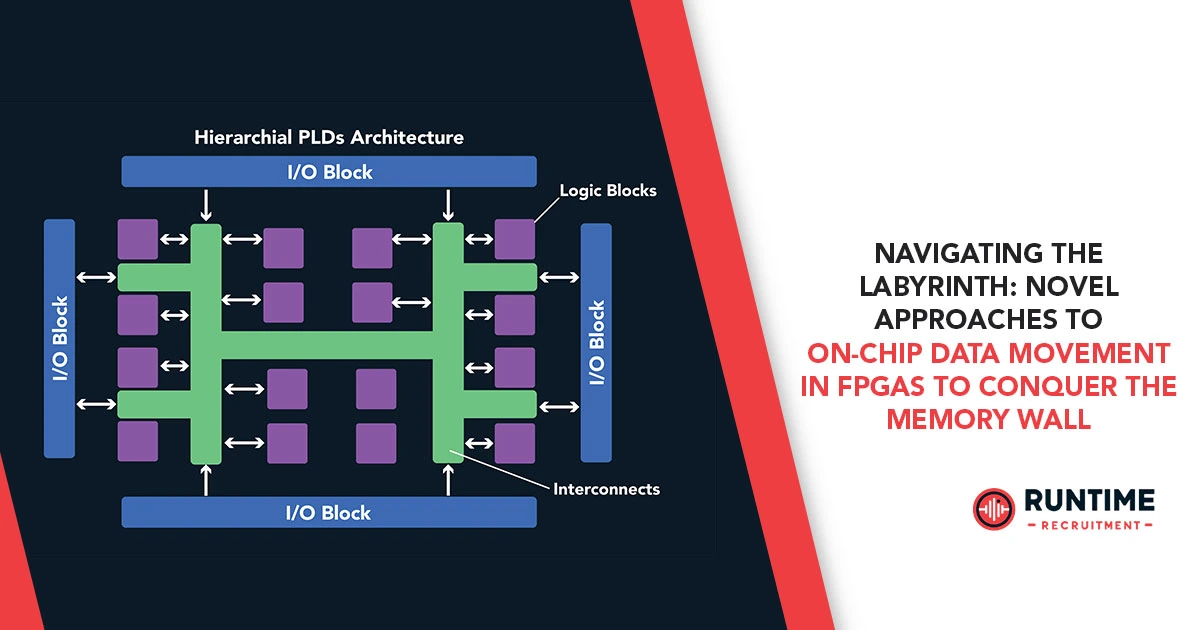
Before we explore solutions, it’s crucial to understand the memory landscape within an FPGA. Modern FPGAs typically feature a multi-level memory hierarchy, each with distinct characteristics:
- Registers: The fastest and smallest form of storage, directly integrated within the logic elements. Ideal for immediate data manipulation and temporary results within a single clock cycle.
- Block RAMs (BRAMs): Dedicated on-chip synchronous RAM blocks, offering higher capacity and significantly lower latency than external memory. BRAMs are highly configurable (e.g., single-port, dual-port, simple dual-port, FIFO) and are the workhorses for on-chip data buffering, look-up tables, and small data sets. Their distributed nature across the FPGA fabric is a key asset.
- UltraRAMs (URAMs): (Specific to Xilinx UltraScale+ FPGAs) Larger, high-density memory blocks designed for applications requiring more substantial on-chip storage than BRAMs, while still offering very high bandwidth.
- External Memory Interfaces (DDR, HBM): Connect FPGAs to off-chip DRAM modules like DDR4 or, increasingly, High Bandwidth Memory (HBM). These offer the largest capacity but suffer from significantly higher latency and lower bandwidth relative to on-chip memories.
The core of the memory wall problem in FPGAs stems from the immense speed difference between on-chip computation and access to external memory. Even within the FPGA, inefficient movement of data between distributed BRAMs or from BRAMs to processing elements can become a bottleneck. Therefore, optimizing on-chip data movement is paramount.
Novel Approaches to On-Chip Data Movement
To effectively combat the memory wall, embedded engineers are adopting a range of innovative strategies that go beyond simple data buffering. These approaches focus on maximizing data reuse, minimizing external memory accesses, and intelligently orchestrating data flow across the FPGA fabric.
1. Dataflow-Centric Design and Pipelining
One of the most powerful paradigms for on-chip data movement in FPGAs is dataflow programming. Instead of traditional imperative execution, dataflow designs model computation as a network of interconnected processing elements (PEs) where data “flows” from one operation to the next.
- Deep Pipelining: FPGAs excel at pipelining, breaking down complex computations into a series of sequential stages. Each stage operates on a different piece of data concurrently, leading to a dramatic increase in throughput. By carefully designing pipelines, engineers can ensure that data is continuously streaming through the processing elements, effectively masking memory latency. This involves strategically placing registers between pipeline stages to maximize clock frequency and avoid combinational logic paths that span across large sections of the FPGA.
- Stream-Based Architectures: Many modern high-level synthesis (HLS) tools encourage stream-based data movement, where data is treated as continuous streams flowing between functional units via FIFO buffers. This approach naturally lends itself to pipelined designs, reducing the need for explicit memory addressing and maximizing data locality. Data is consumed as soon as it’s produced, minimizing idle cycles.
- Producer-Consumer Models: This is a natural fit for dataflow. Functional blocks are designed as producers or consumers of data, with FIFOs acting as decoupling buffers between them. This allows for asynchronous operation between blocks and handles varying processing rates, preventing stalls due to memory access delays.
2. Advanced On-Chip Memory Architectures
Beyond simply using BRAMs, novel architectural patterns are emerging to optimize their utilization:
- Memory Banking and Partitioning: Instead of a single large memory block, designers can partition data across multiple smaller BRAMs (memory banking). This allows for concurrent access to different banks, significantly increasing the effective memory bandwidth. For example, if an algorithm requires simultaneous access to multiple data streams, dedicating separate BRAMs to each stream can eliminate contention. Careful data placement and addressing are crucial here.
- Distributed Memory for Compute-in-Memory (CiM) Paradigms: While not yet mainstream for FPGAs in the same way as specialized ASICs, the concept of “compute-in-memory” is gaining traction. This involves integrating computational logic directly within or very close to memory blocks. For FPGAs, this can mean designing small, specialized processing units adjacent to BRAMs, allowing for highly localized computation without significant data movement overhead. An example is the concept of “CoMeFa RAMs” which enhance BRAMs with processing elements, enabling parallel compute-in-memory operations [3].
- Scratchpad Memories and Tiling: For iterative algorithms, loading entire datasets from external memory repeatedly is highly inefficient. Scratchpad memories, explicitly managed by the designer, can hold frequently accessed subsets of data. Tiling techniques divide large datasets into smaller, manageable “tiles” that can fit into on-chip memory. Computation is then performed on these tiles, minimizing external memory traffic. Once a tile is processed, the next one is loaded.
3. High-Bandwidth Memory (HBM) Integration
The advent of FPGAs with integrated High Bandwidth Memory (HBM) stacks is a game-changer for tackling the memory wall. HBM provides significantly higher bandwidth and lower latency compared to traditional DDR interfaces, largely due to its 3D-stacked architecture and wide interface.
- Leveraging HBM Channels: HBM typically exposes multiple independent memory channels. FPGA designs can be tailored to exploit this parallelism by mapping different data streams or large data structures to distinct HBM channels. This massively parallel access can dramatically reduce memory access bottlenecks for applications that are inherently data-intensive, such as deep learning inference and high-performance computing.
- Co-optimization of HBM and On-Chip Memory: The true power of HBM is unleashed when it’s intelligently co-optimized with the FPGA’s on-chip memory. HBM can serve as a high-speed “main memory” for the FPGA, while BRAMs and URAMs act as very fast caches or scratchpads for immediate data needs. This multi-level memory hierarchy, with HBM bridging the gap between external DRAM and on-chip SRAM, becomes a formidable weapon against the memory wall.
4. Network-on-Chip (NoC) for Scalability
As FPGA designs grow in complexity and integrate more diverse processing elements, a simple bus-based communication fabric can quickly become a bottleneck. Network-on-Chip (NoC) architectures provide a scalable, packet-switched communication infrastructure within the FPGA.
- Structured Data Movement: NoCs offer a more structured and predictable way to move data between disparate IP blocks, processing clusters, and memory controllers on a large FPGA. This is particularly crucial for multi-die FPGAs (chiplets) where communication across Super Logic Regions (SLRs) can incur significant latency and resource overhead. Hardened NoCs, increasingly common in advanced FPGAs, provide optimized, low-latency paths.
- Congestion Avoidance and Load Balancing: NoCs employ routing algorithms and flow control mechanisms to manage traffic and avoid congestion, ensuring more consistent data movement latency even under heavy loads. This contrasts with traditional shared bus architectures, which are prone to bottlenecks as the number of communicating agents increases.
- Enabling Heterogeneous Integration: With FPGAs often integrated into heterogeneous systems (e.g., alongside CPUs, GPUs), NoCs facilitate efficient data exchange within the FPGA itself and with external components, becoming a critical backbone for complex system-on-chip designs.
5. Resource Scheduling and Data Path Optimization
Beyond architectural choices, fine-grained resource scheduling and data path optimization at the RTL level remain crucial for efficient on-chip data movement.
- Fine-grained Gating and Buffering: Judicious use of clock gating and explicit buffering (FIFOs) between functional units can regulate data flow, prevent stalls, and ensure that data is available precisely when needed. This is about minimizing wasted cycles due to data unavailability.
- Exploiting Data Locality: Arranging computations and data storage to maximize data reuse within on-chip memory minimizes the need to fetch data from slower external sources. This often involves restructuring algorithms to operate on small, highly localized data sets before moving to the next. Loop tiling and blocking are classic examples of this.
- Memory Access Coalescing: Grouping individual memory accesses into larger, contiguous bursts can significantly improve efficiency, especially when interacting with external memory interfaces. This reduces the overhead associated with initiating multiple small transactions.
- Adaptive Data Movement Strategies: For some applications, static data movement strategies might not be optimal. Researchers are exploring adaptive approaches where the data movement patterns can be dynamically reconfigured based on runtime conditions or workload characteristics.
Case Studies and Future Directions
The impact of these novel approaches is evident in various high-performance computing and data-intensive applications. For instance, in neuromorphic computing, FPGAs are being explored as platforms for brain-inspired AI. Here, efficient memory utilization and rapid on-chip data movement are paramount for handling the vast number of synaptic weights and activations. Research in this area actively investigates how memory design patterns can reduce DRAM accesses through near-memory processing and how SRAM can be augmented with ROM caches to mitigate the memory wall.
In deep learning inference, FPGA accelerators heavily rely on highly optimized on-chip memory architectures and dataflow pipelines to achieve high throughput and low latency. Techniques like memory tiling, careful weight quantization, and streaming data through cascaded processing elements are essential to keep the compute units fed and avoid stalls. Some designs even aim for “fully on-chip” solutions for smaller models, storing both input images and hidden layer feature maps directly in FPGA memories to eliminate external DRAM access entirely.
Looking ahead, the evolution of FPGA memory solutions will likely continue on several fronts:
- Further Integration of Emerging Memory Technologies: While HBM is a significant step, future FPGAs may integrate other non-volatile memories (e.g., Resistive RAM – ReRAM, Phase-Change Memory – PCM) directly on-package or even on-die, blurring the lines between computation and storage further.
- Smarter Memory Controllers: More intelligent, perhaps even AI-driven, memory controllers that can predict data access patterns and proactively prefetch data will play a crucial role.
- Higher-Level Abstractions and Tools: As these low-level optimizations become more complex, high-level synthesis (HLS) tools will need to evolve to automatically infer and implement sophisticated data movement strategies from high-level C/C++/OpenCL descriptions, easing the burden on embedded engineers.
- Open-Source Hardware and Standards: The development of open standards and open-source IP for on-chip interconnects and memory interfaces could foster greater innovation and interoperability.
Conclusion: Engineering a Data-Centric Future
The memory wall remains a persistent challenge in FPGA design, but it is by no means an insurmountable one. By embracing novel approaches to on-chip data movement – from dataflow-centric design and advanced memory architectures to the integration of HBM and robust Network-on-Chip solutions – embedded engineers can construct highly efficient and performant FPGA systems. The key lies in shifting the design philosophy from merely “computing on data” to “moving data intelligently to enable computation.” This data-centric mindset, coupled with a deep understanding of FPGA memory hierarchies, is essential for unlocking the full potential of these versatile devices.
Are you an embedded engineer passionate about pushing the boundaries of FPGA performance and tackling complex memory challenges?
RunTime Recruitment specializes in connecting top engineering talent with leading companies at the forefront of hardware acceleration and embedded systems.
If you’re looking for your next impactful role where you can apply your expertise, visit our website or connect with us on LinkedIn.







