Embedded Digital Signal Processing (DSP) applications demand high performance while operating under strict power, memory, and real-time constraints. One of the most effective ways to accelerate DSP algorithms is by leveraging Single Instruction, Multiple Data (SIMD) architectures. SIMD allows a single instruction to process multiple data points simultaneously, dramatically improving throughput for vectorized operations common in signal processing.
In this article, we’ll explore practical SIMD optimization techniques for embedded DSP, covering:
- Understanding SIMD in Embedded DSP
- Key SIMD Architectures for Embedded Systems
- Data Alignment and Memory Access Patterns
- Optimizing Common DSP Kernels with SIMD
- Compiler Intrinsics vs. Hand-Tuned Assembly
- Performance Measurement and Trade-offs
- Real-World Case Studies
By the end, you’ll have actionable insights to maximize the efficiency of your DSP algorithms using SIMD.
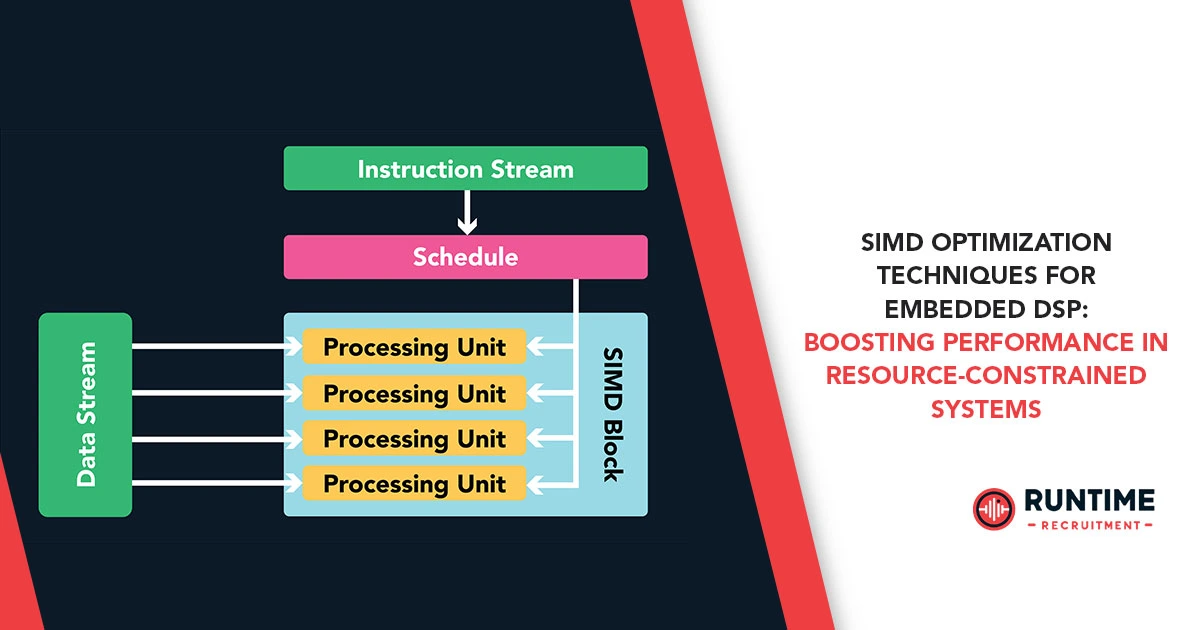
1. Understanding SIMD in Embedded DSP
What is SIMD?
SIMD is a parallel processing technique where a single instruction operates on multiple data elements in parallel. Unlike scalar processing (one operation per data element), SIMD enables:
- Faster FIR/IIR filtering (processing multiple taps at once)
- Efficient FFT computation (parallelizing butterfly operations)
- High-speed matrix operations (used in machine learning on edge devices)
Why SIMD for Embedded DSP?
- Power Efficiency: Fewer clock cycles → Lower energy consumption.
- Real-Time Performance: Meets tight timing constraints in audio, radar, and communications.
- Cost Savings: Achieves high throughput without needing a faster (and more expensive) CPU.
2. Key SIMD Architectures for Embedded Systems
Different embedded processors support varying SIMD instruction sets. Here are the most common ones:
ARM Cortex-M & NEON
- Cortex-M4/M7: Supports ARM’s DSP extensions (e.g., SMLAD for multiply-accumulate).
- Cortex-A with NEON: Advanced SIMD for floating-point and integer operations.
RISC-V Vector Extensions (RVV)
- Emerging standard for open-source cores, offering scalable SIMD capabilities.
TI C6000 DSP (C66x)
- VLIW + SIMD: Texas Instruments’ DSPs use wide SIMD registers (e.g., 128-bit operands).
Intel/AMD x86 SSE/AVX
- Relevant for high-performance embedded Linux systems (e.g., industrial PCs).
3. Data Alignment and Memory Access Patterns
Aligning Data for SIMD
SIMD operations perform best when data is aligned to the SIMD register width (e.g., 16-byte alignment for 128-bit NEON). Misaligned accesses cause penalties.
Best Practices:
- Use __attribute__((aligned(16))) in C/C++.
- Allocate memory with posix_memalign() instead of malloc().
Efficient Memory Access
- Sequential Access: SIMD loves linear, contiguous data.
- Avoid Strided Access: Non-unit strides (e.g., array[i][j] with large j) hurt performance.
- Loop Unrolling: Reduces loop overhead and improves pipelining.
4. Optimizing Common DSP Kernels with SIMD
FIR Filter Optimization
A standard FIR filter computes:
y[n]=∑k=0N−1h[k]⋅x[n−k]
y[n]=
k=0
∑
N−1
h[k]⋅x[n−k]
SIMD Optimization Steps:
- Load multiple coefficients (h[k]) and samples (x[n-k]) into SIMD registers.
- Use multiply-accumulate (MAC) instructions.
- Sum partial results horizontally.
Example (ARM NEON Intrinsics):
#includeFFT Acceleration
FFTs involve complex multiplications and additions. SIMD can parallelize:
- Butterfly operations (radix-2/4).
- Twiddle factor multiplications.
NEON Example for Radix-2 Butterfly:
float32x4x2_t butterfly(float32x4x2_t a, float32x4x2_t b, float32x4_t twiddle) { float32x4_t tmp_re = vsubq_f32(a.val[0], b.val[0]); float32x4_t tmp_im = vsubq_f32(a.val[1], b.val[1]); a.val[0] = vaddq_f32(a.val[0], b.val[0]); a.val[1] = vaddq_f32(a.val[1], b.val[1]); b.val[0] = vmulq_f32(tmp_re, twiddle); // Complex multiply b.val[1] = vmulq_f32(tmp_im, twiddle); return (float32x4x2_t){a.val[0], a.val[1]}; }Matrix Multiplication
Common in neural networks (e.g., CNN layers).
- Block processing with SIMD improves cache locality.
- 4×4 or 8×8 tiles work well with 128-bit registers.
5. Compiler Intrinsics vs. Hand-Tuned Assembly
Compiler Intrinsics (Recommended for Most Cases)
- Pros: Portable, maintainable, good performance.
- Cons: May not always generate optimal code.
Example (NEON Intrinsic for Dot Product):
float dot_product(float *a, float *b, int len) { float32x4_t sum = vdupq_n_f32(0.0f); for (int i = 0; i < len; i += 4) { float32x4_t va = vld1q_f32(&a[i]); float32x4_t vb = vld1q_f32(&b[i]); sum = vmlaq_f32(sum, va, vb); } return vaddvq_f32(sum); }Hand-Written Assembly (For Extreme Optimization)
- Pros: Maximum control over pipeline and register usage.
- Cons: Hard to maintain, processor-specific.
Example (ARM Assembly for FIR Filter):
fir_filter_asm: vmov.i32 q0, #0 ; Initialize accumulator loop: vld1.32 {q1}, [r1]! ; Load samples vld1.32 {q2}, [r2]! ; Load coefficients vmla.f32 q0, q1, q2 ; Multiply-accumulate subs r3, r3, #4 ; Decrement loop counter bne loop vadd.f32 d0, d0, d1 ; Horizontal add vmov.f32 r0, s0 ; Store result bx lr6. Performance Measurement and Trade-offs
Benchmarking SIMD Code
- Cycle Counting: Use processor-specific counters (e.g., ARM DWT).
- Throughput vs. Latency: SIMD improves throughput but may increase latency.
- Power Consumption: Measure with energy probes (e.g., Joulescope).
When NOT to Use SIMD
- Small data sets (overhead outweighs benefits).
- Highly branch-dependent code (SIMD prefers data parallelism).
7. Real-World Case Studies
Case 1: Audio Processing on Cortex-M7
- Problem: Real-time 10-band EQ on a low-power microcontroller.
- Solution: SIMD-optimized FIR filters reduced CPU load by 60%.
Case 2: Radar Signal Processing on TI C66x
- Problem: FFT computation bottleneck.
- Solution: Hand-tuned SIMD assembly sped up FFT by 4x.
Case 3: Embedded Vision on RISC-V
- Problem: Convolutional layers in a CNN.
- Solution: RVV-accelerated matrix ops improved inference speed by 3.5x.
Conclusion
SIMD optimization is a game-changer for embedded DSP, enabling high performance without excessive power or cost.
Key takeaways:
✅ Choose the right SIMD ISA (NEON, RVV, C66x).
✅ Optimize memory access (alignment, stride, locality).
✅ Leverage intrinsics for maintainable code.
✅ Benchmark rigorously to validate improvements.
By applying these techniques, you can unlock the full potential of your embedded DSP system.







