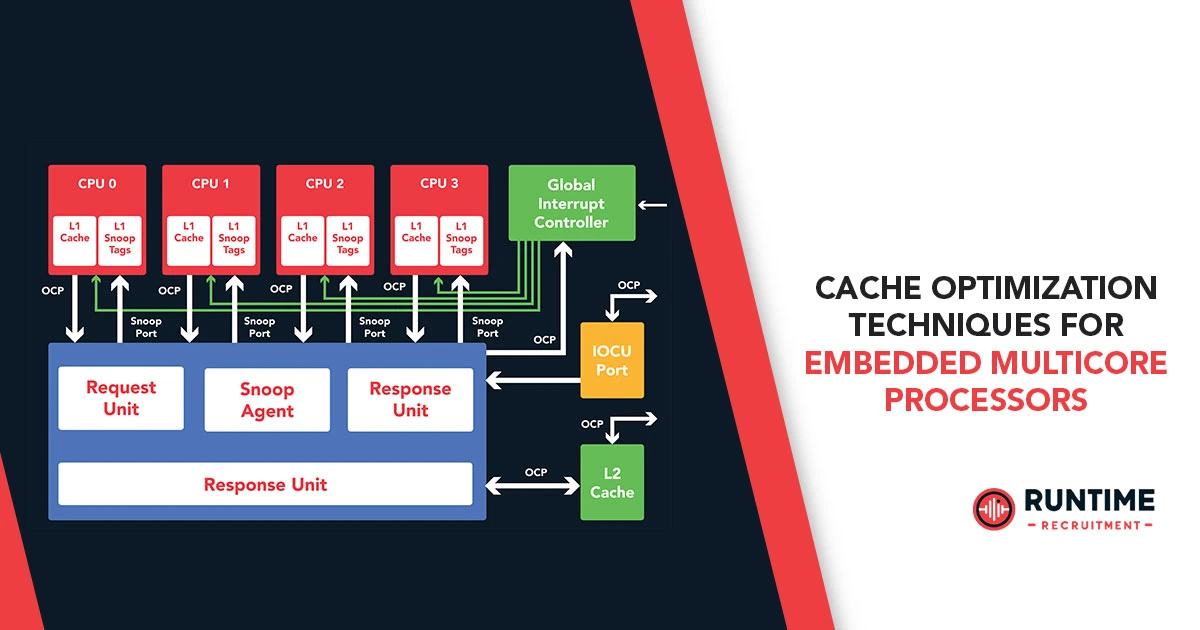
Embedded systems are increasingly adopting multicore processors to meet the growing demand for high-performance, energy-efficient computing. However, as the number of cores increases, so does the complexity of managing shared resources, particularly cache memory.
Efficient cache utilization is critical in embedded systems where real-time constraints, power consumption, and deterministic behavior are paramount.
This article explores key cache optimization techniques for embedded multicore processors, covering hardware and software strategies to minimize cache misses, reduce contention, and improve overall system performance.
1. Understanding Cache Architecture in Multicore Embedded Systems
Before diving into optimization techniques, it’s essential to understand how caches work in multicore processors.
1.1 Cache Hierarchy in Multicore Processors
Modern embedded multicore processors typically feature:
- L1 Cache (Per-core private cache) – Fast but small, split into instruction (L1i) and data (L1d) caches.
- L2 Cache (Shared or private per core) – Larger than L1, often shared among cores to reduce latency.
- L3 Cache (Shared among all cores, if present) – Larger but slower, used to minimize off-chip memory access.
1.2 Cache Coherency in Multicore Systems
Since multiple cores share data, maintaining cache coherency is crucial. Protocols like MESI (Modified, Exclusive, Shared, Invalid) ensure that all cores see a consistent memory view. However, coherency traffic can introduce overhead, necessitating optimization.
1.3 Challenges in Multicore Cache Optimization
- False Sharing – Cores invalidate each other’s cache lines unnecessarily.
- Cache Thrashing – Frequent evictions due to contention.
- Non-Deterministic Latency – Hard to predict in real-time systems.
2. Hardware-Level Cache Optimization Techniques
2.1 Cache Partitioning
- Static Partitioning – Assigns fixed cache portions to cores, preventing interference.
- Dynamic Partitioning – Adjusts cache allocation based on workload (e.g., Intel CAT).
Use Case: Real-time systems where predictable cache behavior is required.
2.2 Way-Pinning in Set-Associative Caches
- Locks specific cache ways to critical tasks, reducing evictions.
- Helps in mixed-criticality systems where high-priority tasks must not be evicted.
2.3 Non-Uniform Cache Architecture (NUCA)
- Divides a large shared cache into banks with varying access latencies.
- Reduces contention by placing frequently accessed data in closer banks.
2.4 Selective Cache Bypassing
- Skips caching for certain data (e.g., streaming data) to avoid pollution.
- Useful for DMA-driven applications where data is used once.
2.5 Prefetching Techniques
- Hardware Prefetching – Predicts and fetches data before it’s needed.
- Software Prefetching – Explicit prefetch instructions (__builtin_prefetch in GCC).
Trade-off: Reduces latency but may increase power consumption.
3. Software-Level Cache Optimization Techniques
3.1 Data Alignment and Padding
- Align structures to cache line boundaries to prevent false sharing.
Example:
struct __attribute__((aligned(64))) thread_data {
int counter; // Padded to avoid sharing a cache line
};
3.2 Loop Optimizations
- Loop Tiling (Blocking) – Breaks loops into smaller blocks that fit in cache.
- Loop Unrolling – Reduces branch overhead but may increase register pressure.
3.3 Memory Access Pattern Optimization
- Sequential Access – Improves spatial locality.
- Strided Access Minimization – Reduces cache thrashing.
3.4 Thread Affinity and Core Pinning
- Binds threads to specific cores to improve cache locality.
Linux example:
cpu_set_t cpuset;
CPU_ZERO(&cpuset);
CPU_SET(core_id, &cpuset);
pthread_setaffinity_np(thread, sizeof(cpu_set_t), &cpuset);
3.5 Lock-Free and Wait-Free Algorithms
- Reduces cache line bouncing in shared data structures.
- Techniques:
- Atomic operations (e.g., std::atomic in C++).
- Read-Copy-Update (RCU) for low-contention scenarios.
3.6 Compiler Directives for Cache Control
- GCC/Clang: __builtin_prefetch, __attribute__((aligned)).
- ARM Caches: Use PLD (Preload Data) instructions.
4. Real-World Case Studies
4.1 Automotive Multicore Systems
- Challenge: Real-time sensor data processing with deterministic latency.
- Solution: Cache partitioning + way-pinning for critical control tasks.
4.2 Embedded AI at the Edge
- Challenge: Running CNN models efficiently on multicore SoCs.
- Solution: Loop tiling + software prefetching for matrix operations.
4.3 Industrial Robotics
- Challenge: Minimizing jitter in motion control loops.
- Solution: Core pinning + lock-free shared memory access.
5. Tools for Cache Performance Analysis
5.1 Hardware Performance Counters
- ARM: perf stat -e cache-misses,cache-references.
- Intel: VTune Profiler for cache utilization metrics.
5.2 Cache Simulation Tools
- gem5 – Simulates cache behavior before hardware deployment.
- Valgrind (Cachegrind) – Profiles cache misses in software.
5.3 Linux Perf and Ftrace
- Analyze cache behavior in real-time systems.
6. Future Trends in Cache Optimization
- Machine Learning for Cache Prefetching – Predictive algorithms for better prefetch accuracy.
- Persistent Memory Caching – Reducing DRAM dependency in embedded systems.
- Heterogeneous Cache Architectures – Combining SRAM, MRAM, and STT-RAM for power efficiency.
Conclusion
Optimizing cache performance in embedded multicore processors is a multifaceted challenge requiring a combination of hardware-aware design and software-level tuning. Techniques such as cache partitioning, way-pinning, loop optimizations, and thread affinity can significantly improve performance and determinism.
As embedded systems continue to evolve, engineers must stay updated on emerging trends like ML-driven prefetching and heterogeneous caching to maintain efficiency in next-generation designs.
By applying these cache optimization strategies, embedded developers can ensure their multicore systems deliver maximum performance while meeting real-time and power constraints.







