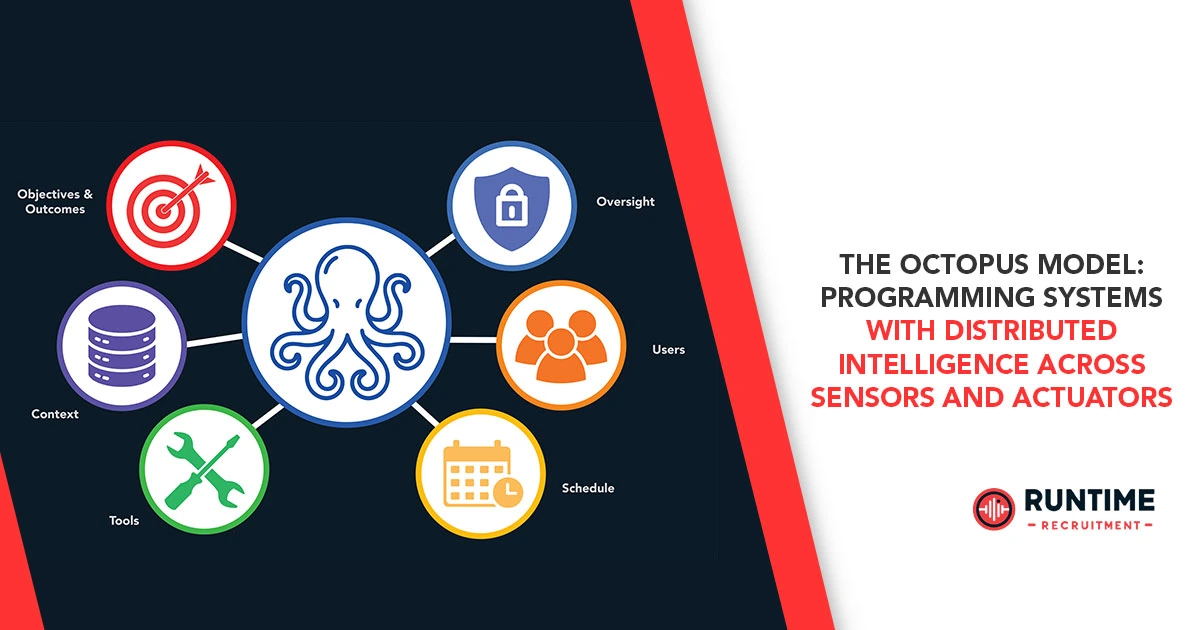
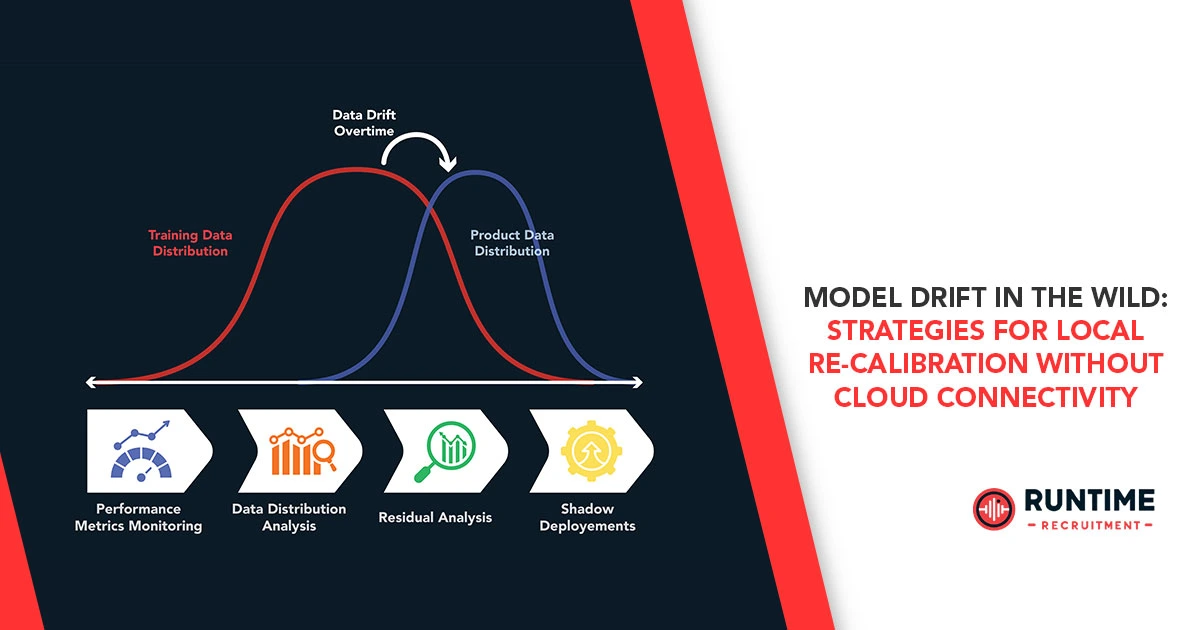
General5 June 2026
The Great Transition: Identifying Mid-Level Engineers Ready to Step Into Senior Architectural Roles
The embedded engineering landscape is facing a profound bottleneck. As technologies like Edge AI, advanced industrial automation, and connected IoT devices proliferate, the demand for sophisticated hardware-software co-design has never been higher. Yet, while there is a steady pipeline of junior and mid-level engineers capable of writing solid firmware, there is a critical shortage of [...]
Read More >>