In the controlled environment of a laboratory or a high-performance computing cluster, Machine Learning (ML) models are masterpieces of mathematical precision. We feed them curated datasets, tune their hyperparameters until the loss curves flatten, and achieve validation accuracies that inspire confidence. However, for the embedded engineer, the deployment of an ML model is not the end of the journey; it is the beginning of a battle against reality.
Once a model is flashed onto a microcontroller (MCU) or an Edge AI accelerator and sent “into the wild”, whether that is a remote industrial sensor, an undersea autonomous vehicle, or a wearable medical device; it begins to decay. This phenomenon, known as Model Drift, is the silent killer of Edge AI reliability. When cloud connectivity is a given, drift is a manageable hurdle. But when the system must operate in a vacuum of connectivity, the challenge shifts from simple monitoring to the complex engineering of Local Re-Calibration.
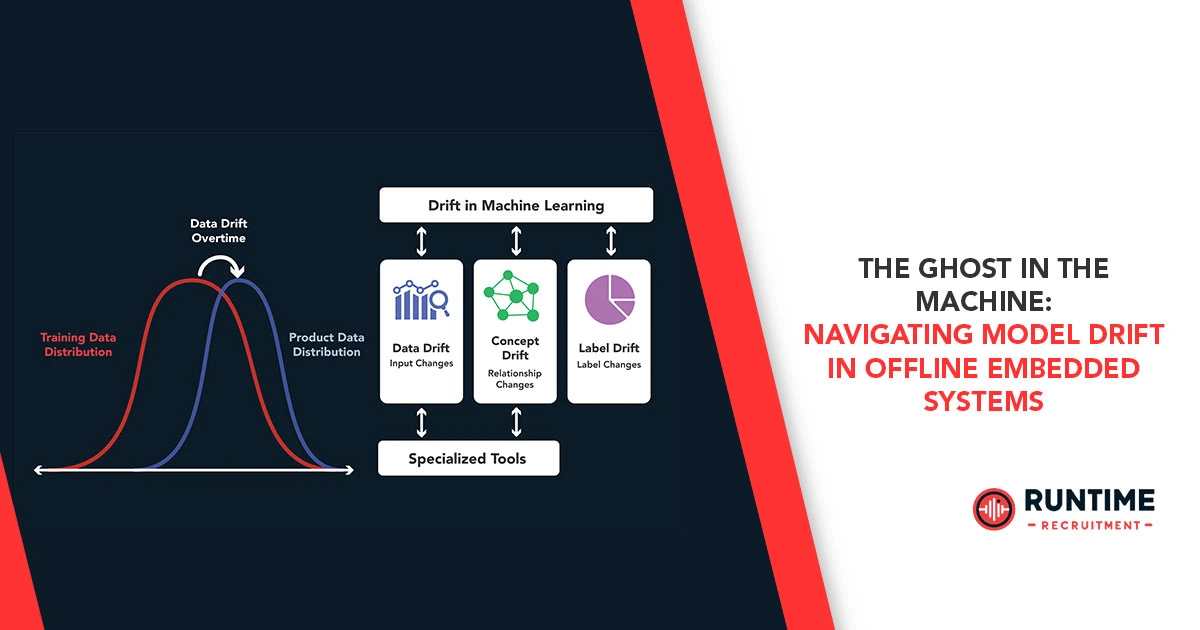
Understanding the Anatomy of Drift
To solve drift at the edge, we must first categorize what is actually changing. Drift is rarely a singular failure; it is usually the result of three distinct shifts in the data-model relationship.
1. Concept Drift (The “Rules” Change)
In Concept Drift, the statistical relationship between the input data and the target labels changes over time. Imagine an anomaly detection model for a CNC machine. Over months of operation, the mechanical bearings wear down naturally. What was “normal” vibration six months ago is now different, even if the machine is still functioning perfectly. The fundamental definition of “normal” has drifted.
2. Covariate Shift (The “Inputs” Change)
Here, the distribution of the input data (P(X)) changes, even if the underlying concept (P(Y∣X)) remains the same. A classic example is a vision-based agricultural drone. A model trained on lush green fields in the spring will face a covariate shift when the dry season turns the landscape brown. The logic of identifying a weed hasn’t changed, but the environment in which it must be identified has.
3. Sensor Degradation (The “Eyes” Fail)
In the embedded world, we cannot ignore the hardware. Salt spray, thermal cycling, and radiation can cause sensor bias or increased noise floor. If a temperature sensor begins to report a +2°C bias due to aging, the model’s performance will degrade as if the environment itself had changed.
The Connectivity Paradox
Standard MLOps (Machine Learning Operations) relies on a “Closed Loop” via the cloud. The edge device sends telemetry and samples to a powerful server; the server detects drift, retrains a new model on a massive GPU cluster, and pushes an OTA (Over-the-Air) update.
In many critical embedded sectors—Defense, Mining, Medical, and Deep-Sea Exploration—this loop is broken. Connectivity is either physically impossible, strategically dangerous (due to RF signatures), or economically unviable. This necessitates Autonomous Local Re-Calibration: the ability of the firmware to detect its own obsolescence and correct its course using only the resources available on-chip.
Strategy I: Statistical Monitoring via Lightweight Ensembles
Before we can calibrate, we must detect. On resource-constrained devices, we cannot run complex statistical tests on every inference. Instead, we use Integrity Monitors.
The Shadow Model Approach
One effective method is to deploy a “Shadow Model”—a significantly smaller, highly regularized version of the primary model. While the primary model provides high-accuracy inference, the shadow model monitors the distribution of the latent space. If the outputs of the two models begin to diverge beyond a specific Euclidean distance threshold, it triggers a “Drift Alert.”
Statistical Checksums
Embedded engineers can utilize K-S (Kolmogorov-Smirnov) tests or Page-Hinkley tests on the input distributions. By maintaining a running histogram of input features in a circular buffer, the system can compare current windows of data against the baseline distribution recorded during factory calibration.
Strategy II: On-Device Incremental Learning
Once drift is detected, how do we fix it without a GPU? We cannot perform backpropagation on a standard 1500-word article’s worth of code; the memory overhead for gradient storage alone would crash an ARM Cortex-M4.
1. Transfer Learning at the Edge
The most viable path is to freeze the majority of the neural network (the feature extractors) and only retrain the “Head” or the final fully connected layers. These layers contain the most task-specific information. By using Stochastic Gradient Descent (SGD) on just the final weights, we reduce the RAM requirement from megabytes to kilobytes.
2. Online Passive-Aggressive Algorithms
For linear models or SVMs often used in low-power sensing, Passive-Aggressive (PA) algorithms are ideal. If a new data point is classified correctly with a high margin, the model remains “passive” (no changes). If the prediction is wrong or the margin is thin, the model “aggressively” updates its weights to accommodate the new information. This is computationally inexpensive and requires no storage of past data.
Strategy III: Self-Supervised Pseudo-Labeling
The biggest hurdle for offline re-calibration is the lack of “Ground Truth.” In the cloud, humans can label drifted data. At the edge, there is no human.
To overcome this, we use Heuristic Pseudo-Labeling. Suppose an industrial motor controller uses both vibration and current-draw sensors. If the high-accuracy vibration model becomes uncertain, but the simpler, physics-based current-draw model is showing a clear, high-confidence signal, the system can use the output of the current-draw model to “re-label” the vibration data. This “cross-modal teaching” allows the device to adapt its primary model based on secondary, more stable physical laws.
Strategy IV: Hardware-in-the-Loop Re-Normalization
Sometimes, “Model Drift” is actually “Sensor Drift.” Before touching the weights of a neural network, the firmware should attempt to re-normalize the signal chain.
- Dynamic Range Scaling: If the input signal distribution is shifting toward the rails, the firmware can adjust the Gain or Offset of the Analog-to-Front-End (AFE) to bring the signal back into the model’s expected “Goldilocks Zone.”
- Zero-Point Calibration: Implementing periodic “Internal Refence” checks—where the sensor is briefly shunted or exposed to a known internal reference voltage—can eliminate DC bias before it ever reaches the ML inference engine.
Implementation Challenges: The Memory and Power Tax
Implementing these strategies is not free. Re-calibration requires:
- Flash Endurance: Frequent weight updates can wear out NAND/NOR flash. Engineers must implement wear-leveling or use MRAM/FRAM for weight storage.
- Power Budgeting: Training is exponentially more power-hungry than inference. Re-calibration routines should only run during “Charging” states or during periods of low CPU utilization.
- Stability Hazards: What if the model “learns” the wrong thing? Local re-calibration carries the risk of Catastrophic Forgetting or “Positive Feedback Loops” where the model reinforces its own errors. Always maintain a “Factory Default” model in a read-only partition of the flash as a fail-safe.
Conclusion: The New Frontier of Embedded Resilience
Model Drift is an inevitability of the physical world. For the embedded engineer, the goal isn’t to prevent drift, but to build systems resilient enough to handle it. By moving re-calibration from the cloud to the silicon, we create truly autonomous systems—devices that don’t just “act” smart, but “stay” smart, regardless of where they are in the world.
As we push further into the era of Edge AI, the ability to maintain model integrity in “dark” environments will be the differentiator between a prototype and a production-grade product.
Optimize Your Engineering Team
Building resilient Edge AI requires a unique blend of firmware expertise and data science. If you are looking to hire specialists who understand the nuances of embedded machine learning, or if you’re an engineer ready for your next challenge in this field, let’s talk.
Connect with RunTime Recruitment today to find your next lead engineer or career-defining role.







